JavaWeb学习笔记——By Bug
前言
本笔记是Javaweb开发的笔记,需要有一定的前端基础和Java基础 笔记中省略了HTML,CSS,JavaScript,Vue,Ajax相关知识,本笔记中主要记录的是Java相关内容,前端相关笔记,请到本站导航站查阅!
说明: 本笔记为本人学习过程中随手写的笔记,为复习使用,笔记中可能存在遗漏或错误,具体请以官方文档和权威书籍为准!谢谢! 笔记中的一些图片等元素因路径配置问题,可能会发生丢失。 笔记中展示的构造器和方法等的知识点仅为部分内容,完整内容请查阅官方开发文档内容!
参考资料
【黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖Spring+MyBatis+SpringMVC+SpringBoot等)】 https://www.bilibili.com/video/BV1m84y1w7Tb/?share_source=copy_web&vd_source=ea0cf64e8dac6f0193a7e28187a0fccb
Web开发简介
什么是Web? Web即全球广域网,也称万维网,能够通过浏览器访问到的网站
前端web开发
Axios
Axios是对原生的Ajax进行了封装,简化书写
Axios官方文档👇 起步 | Axios中文文档 | Axios中文网 (axios-http.cn)
在vue项目中安装axios
npm i axios
导入axios
xxxxxxxxxximport axios from axios
前端工程化
Vue
见:Vue2+Vue3笔记
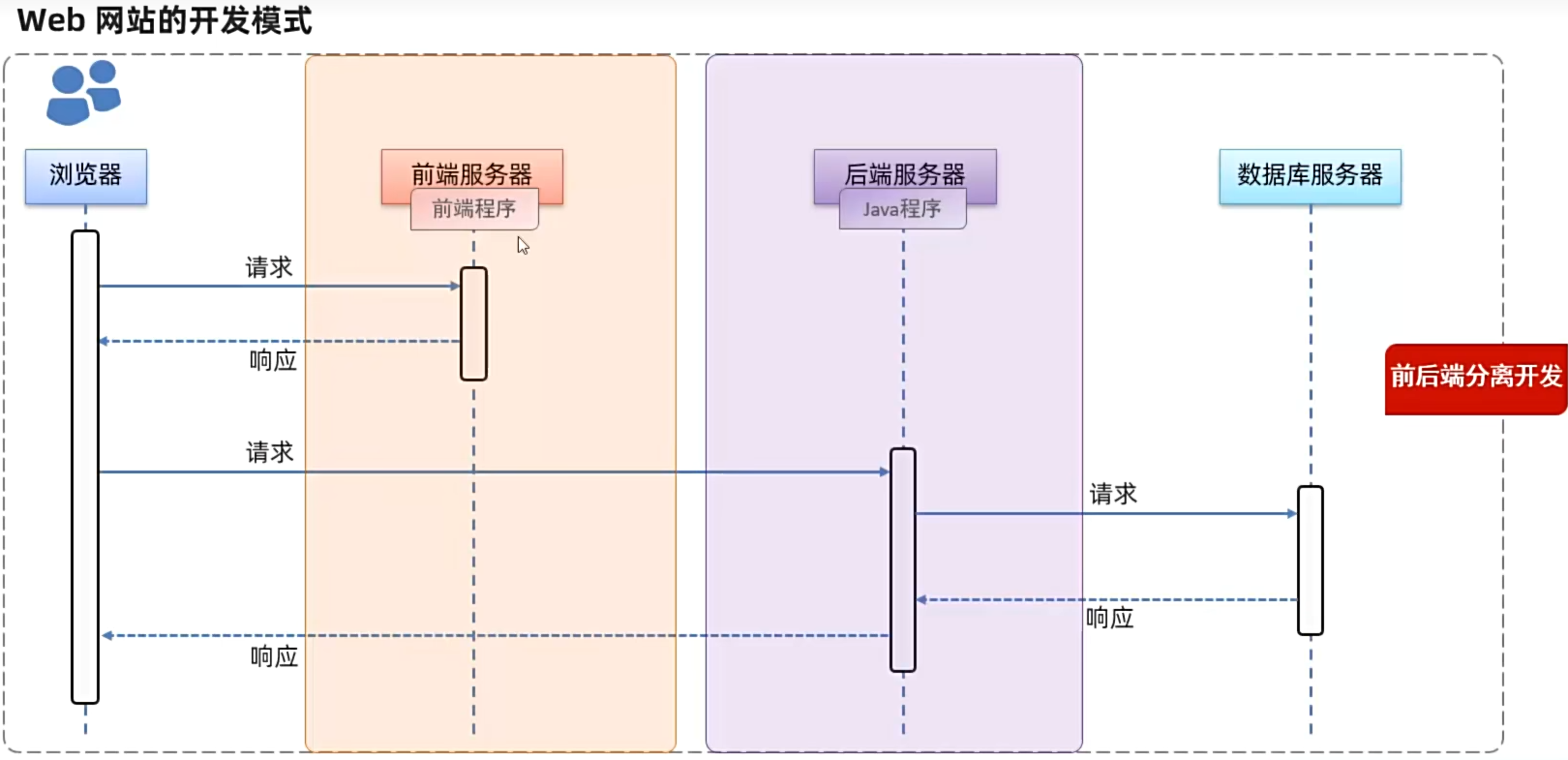
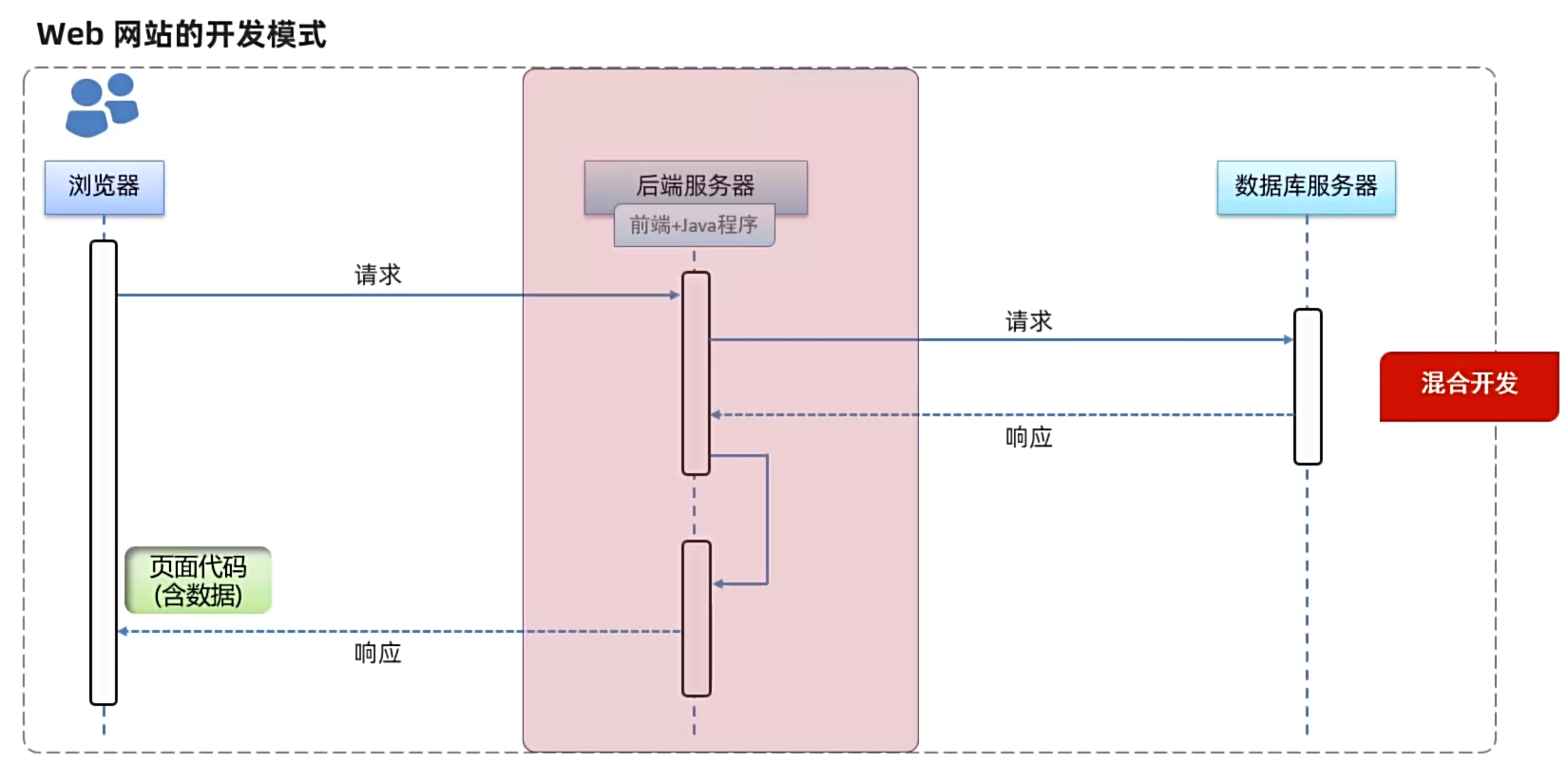
当前主流开发模式:前后端分离模式 前端开发前端页面,后端开发后端程序,前端使用数据时使用API获得相应的数据 以接口文档为标准
流程:需求分析→定义接口文档→前后端并行开发(遵循API文档)→测试(前后端分别测试)→前后端联调测试
接口文档管理平台推荐:YApi,POSTMAN,APIFox
前端工程化开发:模块化(js,css),组件化(UI结构,样式,行为),规范化(结构,编码,接口),自动化(构建,部署,测试)
Element
Element:是一套为开发者,设计师等准备的基于Vue2.0的桌面端组件库 组件:组成网页的部件,如 超链接,按钮,图片,表格,表单等 官网:https://element.eleme.cn/
element-ui组件安装
打开终端,输入以下命令
xxxxxxxxxxnpm i element-ui -S或npm install element-ui@版本号2.15.14在main.js中引入element-ui
ximport ElementUI from 'element-ui';import 'element-ui/lib/theme-chalk/index.css';Vue.use(ElementUI);访问官网文档,选择需要的组件复制后根据需要进行调整 组件 | Element
前端web开发介绍到此结束
下面是后端web开发内容
后端web开发
Maven
Maven是apache旗下的开源项目,用于管理和构建Java项目的工具 官网:Maven – Welcome to Apache Maven
Maven的作用
依赖管理:方便快捷的管理项目的依赖资源(jar包),避免版本冲突问题
提供标准、统一的项目结构
项目构建:标准跨平台的自动化项目构建方式
Maven的介绍
Maven是一个项目管理和构建工具,它是基于项目对象模型(POM)的概念,通过一小段描述信息来管理项目的构建。
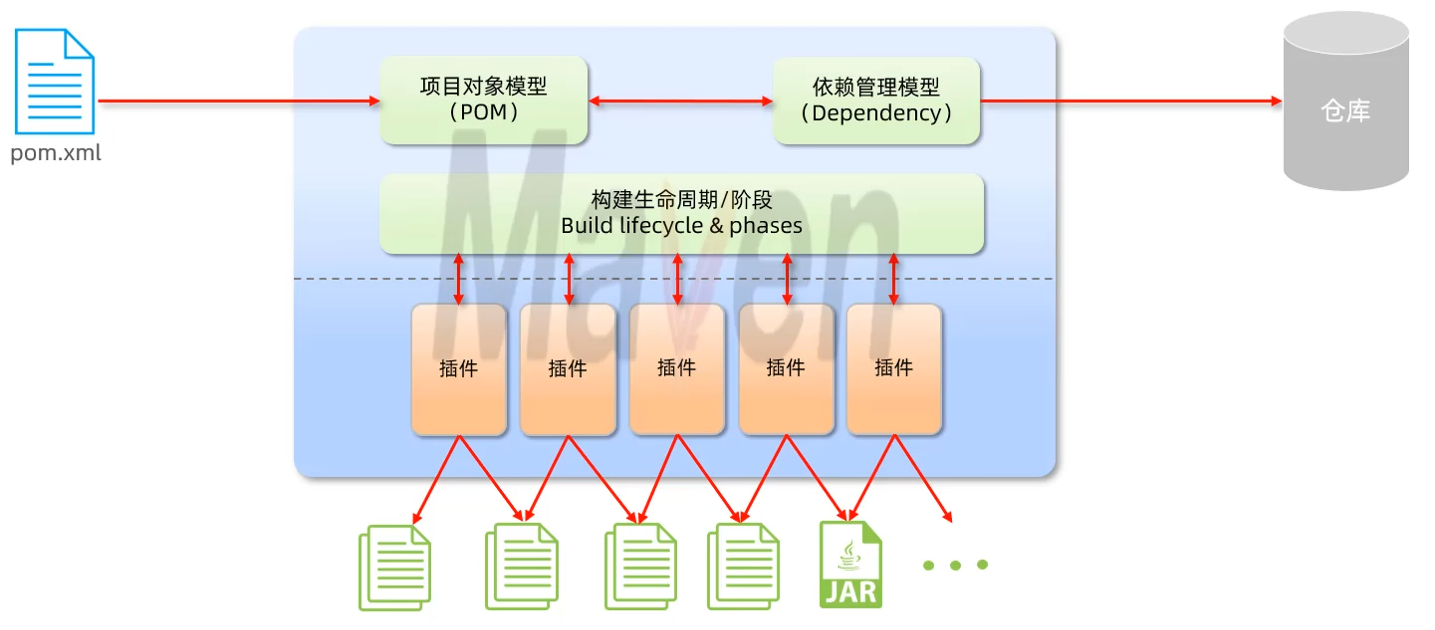
仓库:用于存储资源,管理各种jar包
本地仓库:自己计算机上的仓库
中央仓库:由Maven团队维护的全球统一的仓库
远程仓库:公司团队搭建的私有仓库
Maven的安装
下载并解压压缩包 下载地址:Maven – Download Apache Maven
配置本地仓库:修改conf/settings.xml中的<localRepository>为一个指定目录
xxxxxxxxxx<localRepository>E:\A-learn\JAVA\mavengit</localRepository>配置阿里云私服:修改<mirrors>标签
xxxxxxxxxx<mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/public</url></mirror>配置环境变量:Maven_HOME,并将其Bin目录加入PATH
xxxxxxxxxx检查是否配置完成,执行cmd指令mvn -v
IDEA集成Maven
配置Maven环境
配置当前工程环境
xxxxxxxxxx打开IDEA:File-->Settings-->Build,Execution,Deployment-->Build Tools-->Maven配置对应的安装目录,设置xml目录和仓库目录全局配置
xxxxxxxxxx在欢迎界面,点击customize-->All settings-->Build,Execution,Deployment-->Build Tools-->Maven
创建Maven项目 点击创建项目,选择maven,设置配置项
Maven坐标 Maven坐标是资源的唯一标识,通过该坐标可以唯一定位资源的位置 可以使用坐标来定义或引入项目中需要的依赖
Maven坐标的组成
xxxxxxxxxx<groupId>org.example</groupId>---->定义当前maven项目历史的组织名称<artifactId>untitled</artifactId>---->定义当前Maven项目的名称(模块名称)<version>1.0-SNAPSHOT</version>---->定义当前项目的版本号
Maven依赖管理
依赖配置 依赖:指的当前项目运行所需要的jar包,一个项目中可以引入多个依赖 配置:
在pom.xml中编写<dependencies></dependencies>标签
在标签中使用<dependency>标签引入坐标
xxxxxxxxxx<dependency><groupId></groupId><artifactId></artifactId><version></version></dependency>定义坐标的groupId,artifactId,version
点击刷新按钮,引入新加入的坐标
查找依赖网站:Maven Repository: Search/Browse/Explore (mvnrepository.com)
依赖传递 A项目中依赖的B项目的依赖会传递到A项目 直接依赖:在当前项目中通过依赖配置建立的依赖关系 间接资源:被依赖的资源还依赖了其他资源,当前项目就间接依赖其他资源
排除依赖 主动断开依赖的资源,排除的资源无需指定版本号
xxxxxxxxxx<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.5.6</version><exclusions><exclusion><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId></exclusion></exclusions></dependency>
依赖范围 依赖的jar包默认情况下可以在任何地方使用 使用<scope></scope>标签设置其作用的范围 作用范围:
main(主程序范围内有效)
test(测试程序范围有效)
package(是否参与打包运行)
scope取值 主程序 测试程序 打包 cpmpile(default) Y Y Y test Y provide Y Y runtime Y Y 生命周期 Maven生命周期就是为了对所有的Maven项目构建过程进行抽象和统一 Maven有三套独立的生命周期
clean:清理工作
default:核心工作,如编译,测试,打包,安装,部署等
site:生成报告,发布站点等

clean:移除上次构建生成的文件
compile:编译项目源代码
test:使用合适的单元测试框架运行测试
package:将编译后的文件打包
install:安装项目到本地仓库
SpringBoot Web基础
Spring官网:Spring | Home
SpringBoot可以帮助快速构建应用程序,简化开发,提高效率
SpringBoot Web入门
补充教程:IDEA专业版 注意:本方法来源于网络,安全性请自行权衡!如果不放心,可前往官网申请学习产品。
如安装了社区版,请先卸载,到官网下载专业版并安装。 Download IntelliJ IDEA – The Leading Java and Kotlin IDE (jetbrains.com)
下载激活脚本:JetBrains 全家桶激活(2024最新).zip - 蓝奏云 (lanzouh.com)
运行激活脚本,并检查是否激活成功
也可以申请学习版,申请地址:JetBrains 学习产品
新建第一个springboot应用 需求:使用springBoot开发一个web应用,浏览器发出请求/hello时,返回一个HELLO WORLD字符串
创建springBoot工程(请下载专业版)
构建工具选择Maven,依赖选SpringWeb
定义一个请求处理类
xxxxxxxxxxpackage org.example.chuli;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class returnhello {@RequestMapping("/hello")public String hello(){System.out.printf("hello");return "hello";}}启动项目:启动创建项目时自动创建的启动类
访问:
xxxxxxxxxxhttp://localhost:8080/hello
HTTP协议
概述
HTTP:即超文本传输协议,规定了浏览器与服务器之间的数据传输规则

特点
基于TCP协议:面向连接,安全
基于请求--响应模型的:一次请求对应一次响应
HTTP协议是无状态的协议:对于事务的处理没有记忆能力。每次请求和响应都是独立的 优点:速度快 缺点:多次请求之间不能共享数据
请求协议
请求格式:
请求行:请求数据的第一行(包含请求方式,资源路径,协议)
请求头:第二行开始,格式为 key:value
请求体:在post请求最后,用于存放请求参数
Get与post请求区别 GET:请求参数在请求行中,没有请求体。 POST:请求参数在请求体中,POST请求大小没有限制。
请求方式
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 从服务器获取资源。用于请求数据而不对数据进行更改。例如,从服务器获取网页、图片等。 |
| 2 | POST | 向服务器发送数据以创建新资源。常用于提交表单数据或上传文件。发送的数据包含在请求体中。 |
| 3 | PUT | 向服务器发送数据以更新现有资源。如果资源不存在,则创建新的资源。与 POST 不同,PUT 通常是幂等的,即多次执行相同的 PUT 请求不会产生不同的结果。 |
| 4 | DELETE | 从服务器删除指定的资源。请求中包含要删除的资源标识符。 |
| 5 | PATCH | 对资源进行部分修改。与 PUT 类似,但 PATCH 只更改部分数据而不是替换整个资源。 |
| 6 | HEAD | 类似于 GET,但服务器只返回响应的头部,不返回实际数据。用于检查资源的元数据(例如,检查资源是否存在,查看响应的头部信息)。 |
| 7 | OPTIONS | 返回服务器支持的 HTTP 方法。用于检查服务器支持哪些请求方法,通常用于跨域资源共享(CORS)的预检请求。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于诊断。客户端可以查看请求在服务器中的处理路径。 |
| 9 | CONNECT | 建立一个到服务器的隧道,通常用于 HTTPS 连接。客户端可以通过该隧道发送加密的数据。 |
常用的HTTP请求头
| 协议头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Accept | 可接受的响应内容类型(Content-Types)。 | Accept: text/plain | 固定 |
| Accept-Charset | 可接受的字符集 | Accept-Charset: utf-8 | 固定 |
| Accept-Encoding | 可接受的响应内容的编码方式。 | Accept-Encoding: gzip, deflate | 固定 |
| Accept-Language | 可接受的响应内容语言列表。 | Accept-Language: en-US | 固定 |
| Accept-Datetime | 可接受的按照时间来表示的响应内容版本 | Accept-Datetime: Sat, 26 Dec 2015 17:30:00 GMT | 临时 |
| Authorization | 用于表示HTTP协议中需要认证资源的认证信息 | Authorization: Basic OSdjJGRpbjpvcGVuIANlc2SdDE== | 固定 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制。 | Cache-Control: no-cache | 固定 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive``Connection: Upgrade | 固定 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie | Cookie: $Version=1; Skin=new; | 固定:标准 |
| Content-Length | 以8进制表示的请求体的长度 | Content-Length: 348 | 固定 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 | Content-MD5: oD8dH2sgSW50ZWdyaIEd9D== | 废弃 |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) | Content-Type: application/x-www-form-urlencoded | 固定 |
| Date | 发送该消息的日期和时间(以RFC 7231中定义的"HTTP日期"格式来发送) | Date: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Expect | 表示客户端要求服务器做出特定的行为 | Expect: 100-continue | 固定 |
| From | 发起此请求的用户的邮件地址 | From: user@itbilu.com | 固定 |
| Host | 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 | Host: www.itbilu.com:80``Host: www.itbilu.com | 固定 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 | If-Match: "9jd00cdj34pss9ejqiw39d82f20d0ikd" | 固定 |
| If-Modified-Since | 允许在对应的资源未被修改的情况下返回304未修改 | If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| If-None-Match | 允许在对应的内容未被修改的情况下返回304未修改( 304 Not Modified ),参考 超文本传输协议 的实体标记 | If-None-Match: "9jd00cdj34pss9ejqiw39d82f20d0ikd" | 固定 |
| If-Range | 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 | If-Range: "9jd00cdj34pss9ejqiw39d82f20d0ikd" | 固定 |
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 | 固定 |
| Origin | 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 | Origin: http://www.itbilu.com | 固定: 标准 |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 | Pragma: no-cache | 固定 |
| Proxy-Authorization | 用于向代理进行认证的认证信息。 | Proxy-Authorization: Basic IOoDZRgDOi0vcGVuIHNlNidJi2== | 固定 |
| Range | 表示请求某个实体的一部分,字节偏移以0开始。 | Range: bytes=500-999 | 固定 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但RFC制作标准时给拼错了,后来也就将错就错使用Referer了。 | Referer: http://itbilu.com/nodejs | 固定 |
| TE | 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用"trailers"表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为0的块之后还接收到一些额外的字段。 | TE: trailers,deflate | 固定 |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/…… | 固定 |
| Upgrade | 要求服务器升级到一个高版本协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 | 固定 |
| Via | 告诉服务器,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 itbilu.com.com (Apache/1.1) | 固定 |
| Warning | 一个一般性的警告,表示在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning | 固定 |
响应协议
响应组成
响应行
响应头
响应体
响应码介绍
状态码分类
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
状态码解释
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed(预期失败) | 服务器无法满足请求头中 Expect 字段指定的预期行为。 |
| 418 | I'm a teapot | 状态码 418 实际上是一个愚人节玩笑。它在 RFC 2324 中定义,该 RFC 是一个关于超文本咖啡壶控制协议(HTCPCP)的笑话文件。在这个笑话中,418 状态码是作为一个玩笑加入到 HTTP 协议中的。 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
常用的HTTP响应头
| 响应头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Access-Control-Allow-Origin | 指定哪些网站可以跨域源资源共享 | Access-Control-Allow-Origin: * | 临时 |
| Accept-Patch | 指定服务器所支持的文档补丁格式 | Accept-Patch: text/example;charset=utf-8 | 固定 |
| Accept-Ranges | 服务器所支持的内容范围 | Accept-Ranges: bytes | 固定 |
| Age | 响应对象在代理缓存中存在的时间,以秒为单位 | Age: 12 | 固定 |
| Allow | 对于特定资源的有效动作; | Allow: GET, HEAD | 固定 |
| Cache-Control | 通知从服务器到客户端内的所有缓存机制,表示它们是否可以缓存这个对象及缓存有效时间。其单位为秒 | Cache-Control: max-age=3600 | 固定 |
| Connection | 针对该连接所预期的选项 | Connection: close | 固定 |
| Content-Disposition | 对已知MIME类型资源的描述,浏览器可以根据这个响应头决定是对返回资源的动作,如:将其下载或是打开。 | Content-Disposition: attachment; filename="fname.ext" | 固定 |
| Content-Encoding | 响应资源所使用的编码类型。 | Content-Encoding: gzip | 固定 |
| Content-Language | 响就内容所使用的语言 | Content-Language: zh-cn | 固定 |
| Content-Length | 响应消息体的长度,用8进制字节表示 | Content-Length: 348 | 固定 |
| Content-Location | 所返回的数据的一个候选位置 | Content-Location: /index.htm | 固定 |
| Content-MD5 | 响应内容的二进制 MD5 散列值,以 Base64 方式编码 | Content-MD5: IDK0iSsgSW50ZWd0DiJUi== | 已淘汰 |
| Content-Range | 如果是响应部分消息,表示属于完整消息的哪个部分 | Content-Range: bytes 21010-47021/47022 | 固定 |
| Content-Type | 当前内容的MIME类型 | Content-Type: text/html; charset=utf-8 | 固定 |
| Date | 此条消息被发送时的日期和时间(以RFC 7231中定义的"HTTP日期"格式来表示) | Date: Tue, 15 Nov 1994 08:12:31 GMT | 固定 |
| ETag | 对于某个资源的某个特定版本的一个标识符,通常是一个 消息散列 | ETag: "737060cd8c284d8af7ad3082f209582d" | 固定 |
| Expires | 指定一个日期/时间,超过该时间则认为此回应已经过期 | Expires: Thu, 01 Dec 1994 16:00:00 GMT | 固定: 标准 |
| Last-Modified | 所请求的对象的最后修改日期(按照 RFC 7231 中定义的“超文本传输协议日期”格式来表示) | Last-Modified: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Link | 用来表示与另一个资源之间的类型关系,此类型关系是在RFC 5988中定义 | Link:; rel="alternate" | 固定 |
| Location | 用于在进行重定向,或在创建了某个新资源时使用。 | Location: http://www.itbilu.com/nodejs | 固定 |
| P3P | P3P策略相关设置 | P3P: CP="This is not a P3P policy! | 固定 |
| Pragma | 与具体的实现相关,这些响应头可能在请求/回应链中的不同时候产生不同的效果 | Pragma: no-cache | 固定 |
| Proxy-Authenticate | 要求在访问代理时提供身份认证信息。 | Proxy-Authenticate: Basic | 固定 |
| Public-Key-Pins | 用于防止中间攻击,声明网站认证中传输层安全协议的证书散列值 | Public-Key-Pins: max-age=2592000; pin-sha256="……"; | 固定 |
| Refresh | 用于重定向,或者当一个新的资源被创建时。默认会在5秒后刷新重定向。 | Refresh: 5; url=http://itbilu.com | |
| Retry-After | 如果某个实体临时不可用,那么此协议头用于告知客户端稍后重试。其值可以是一个特定的时间段(以秒为单位)或一个超文本传输协议日期。 | 示例1:Retry-After: 120示例2: Retry-After: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Server | 服务器的名称 | Server: nginx/1.6.3 | 固定 |
| Set-Cookie | 设置HTTP cookie | Set-Cookie: UserID=itbilu; Max-Age=3600; Version=1 | 固定: 标准 |
| Status | 通用网关接口的响应头字段,用来说明当前HTTP连接的响应状态。 | Status: 200 OK | |
| Trailer | Trailer用户说明传输中分块编码的编码信息 | Trailer: Max-Forwards | 固定 |
| Transfer-Encoding | 用表示实体传输给用户的编码形式。包括:chunked、compress、 deflate、gzip、identity。 | Transfer-Encoding: chunked | 固定 |
| Upgrade | 要求客户端升级到另一个高版本协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 | 固定 |
| Vary | 告知下游的代理服务器,应当如何对以后的请求协议头进行匹配,以决定是否可使用已缓存的响应内容而不是重新从原服务器请求新的内容。 | Vary: * | 固定 |
| Via | 告知代理服务器的客户端,当前响应是通过什么途径发送的。 | Via: 1.0 fred, 1.1 itbilu.com (nginx/1.6.3) | 固定 |
| Warning | 一般性警告,告知在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning | 固定 |
| WWW-Authenticate | 表示在请求获取这个实体时应当使用的认证模式。 | WWW-Authenticate: Basic | 固定 |
Web服务器
Web服务器是一个软件程序,对HTTP协议的操作进行了封装,使得程序员不需要直接对协议进行操作,使得开发更加便捷。
TomCat介绍
TomCat是一个开源免费的轻量级WEB服务器,支持servlet/jsp少量JavaEE规范
TomCat安装和使用
注意:TomCat已经内置在SpringBoot中,无需再进行下载和安装
TomCat官网:Apache Tomcat® - Welcome!
请求响应
请求(HttpServletRequest):获取请求数据
响应(HttpServletResponse):设置响应数据
BS架构:Browser/server,浏览器/服务器架构
请求
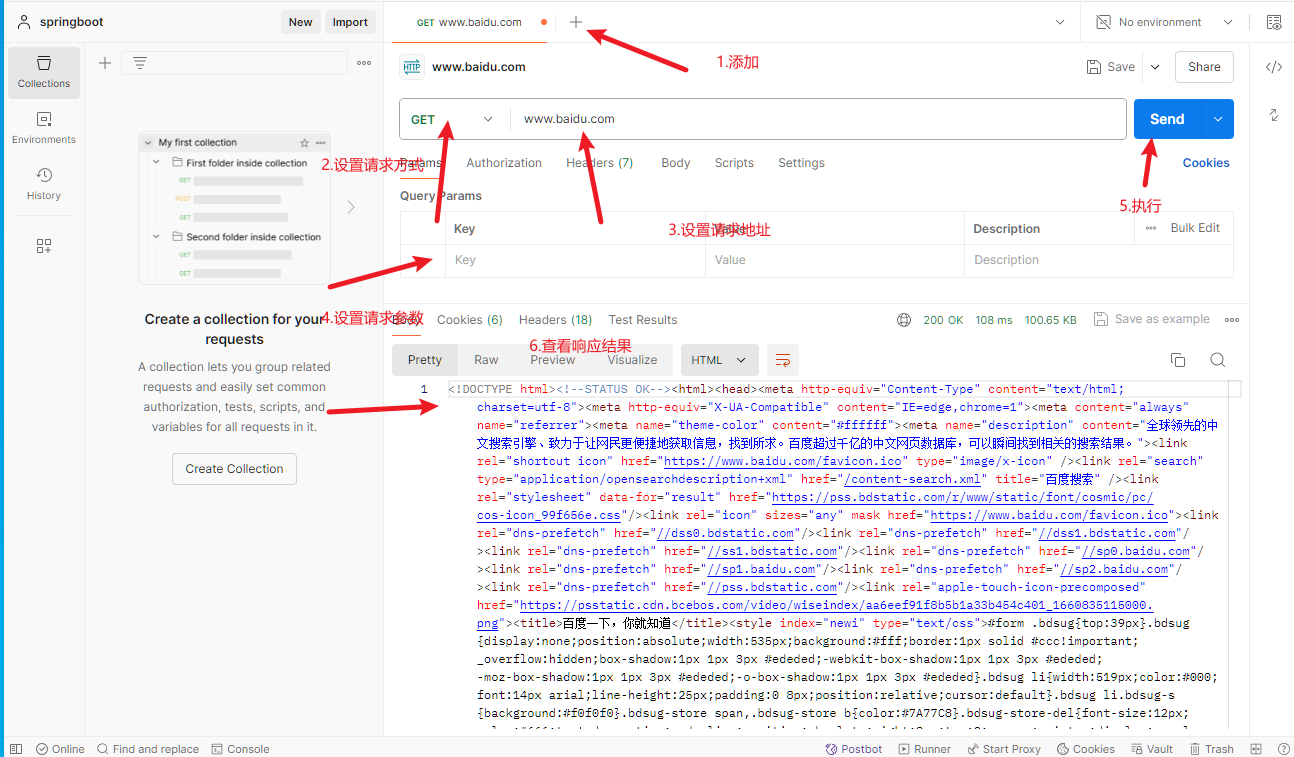
POSTMAN
一款功能强大的网页调试与发送请求的chrome插件,常用于进行接口测试 官网:Postman API Platform | Sign Up for Free 其他工具:APIPOST, APIFOX
下载安装包,并进行安装
注册账号,并进行登录
创建工作空间(workspaces)
简单参数
原始方式(了解) 在原始的web程序中,获取请求参数,需要通过HttpServletRequest对象手动获取
xxxxxxxxxxpackage org.example.chuli;import jakarta.servlet.http.HttpServletRequest;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;public class returnhello {("/hello")public String qingqiu(HttpServletRequest request) {String name = request.getParameter("name");String age = request.getParameter("age");System.out.printf("姓名:" + name + "年龄" + age);return "请求成功"+"姓名:" + name + "年龄" + age;}}测试请求,成功
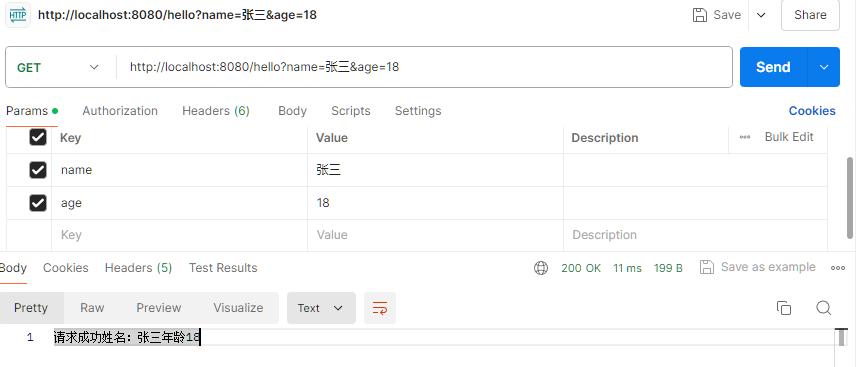
这样的处理方法复杂有难以维护
SpringBoot方式
简单参数:在方法中设置参数名与形参变量名相同,定义形参接收参数
xxxxxxxxxxpackage org.example.chuli;
import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;
public class returnhello { ("/hello") public String qingqiu(String name,Integer age) { System.out.printf("姓名:" + name + "年龄" + age); return "请求成功"+"姓名:" + name + "年龄" + age; }}
如果请求参数与方法形参不一致,可以使用注解@RequestParam进行映射
xxxxxxxxxx public String qingqiu((name = "name") String username, Integer age) { System.out.printf("姓名:" + username + "年龄" + age); return "请求成功"+"姓名:" + username + "年龄" + age; }
实体参数
简单实体对象:请求参数名与形参对象属性名相同,定义一个 类 接收即可
xxxxxxxxxxpackage org.example.chuli;
public class user { private String name; private int age; public user() {}
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String toString() { return "user{" + "name='" + name + '\'' + ", age=" + age + '}'; }}xxxxxxxxxx ("/shiti") public String qingqiu(user u) { System.out.printf(u.toString()); return "ok"; }注意:请求参数名要与形参参数名一致
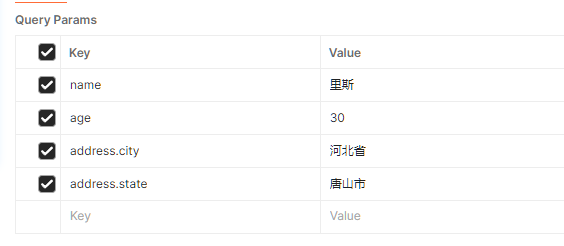
复杂实体对象:请求参数名与形参对象属性名一致,按照对象层次关系即可接收嵌套属性参数
xxxxxxxxxx("/shiti") public String qingqiu(user u) { System.out.println(u.toString()); return "ok"; }xxxxxxxxxxpackage org.example.chuli;
public class user { private String name; private int age; private Address address; public user() {}
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public Address getAddress() { return address; }
public void setAddress(Address address) { this.address = address; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String toString() { return "user{" + "name='" + name + '\'' + ", age=" + age + ", " + address.toString() + '}'; }}xxxxxxxxxxpackage org.example.chuli;
public class Address { private String city; private String state;
public String getCity() { return city; }
public void setCity(String city) { this.city = city; }
public String getState() { return state; }
public void setState(String state) { this.state = state; }
public String toString() { return "Address{" + "city='" + city + '\'' + ", state='" + state + '\'' + '}'; }}请求格式样例:
xxxxxxxxxxhttp://localhost:8080/shiti?name=里斯&age=30&address.city=河北省&address.state=唐山市
数组集合参数
数组参数:请亲参数名与形参数组名称相同,且请求参数有多个,定义一个数组类型的形参即可接收参数
xxxxxxxxxxpackage org.example.chuli;
import java.util.Arrays;
public class hob { private String[] hobby;
public String toString() { return "hob{" + "hpbby=" + Arrays.toString(hobby) + '}'; }
public String[] getHobby() { return hobby; }
public void setHobby(String[] hobby) { this.hobby = hobby; }}xxxxxxxxxx("/Array1") public String qingqiu(hob h) { System.out.println(h.toString()); return "ok"; }xxxxxxxxxx//请求http://localhost:8080/Array1?hobby=唱&hobby=跳&hobby=rap&hobby=篮球
日期参数
使用@DateTimeFormat注解完成日期参数格式转换
xxxxxxxxxx ("/timesave") public String times((pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime time) { System.out.println(time.toString()); return "ok"; }
JSON参数
请求方式:POST 接收json数据一般使用对象接收,JSON数据的键名与形参对象的属性名相同。需要使用@RequestBody标识
xxxxxxxxxxpackage org.example.chuli;
public class Address {//地址对象 private String city; private String state;
}
package org.example.chuli;
public class user {//用户对象 private String name; private int age; private Address address; }xxxxxxxxxx ("/json") public String qingqiu(user u) { System.out.println(u.toString()); return "ok"; }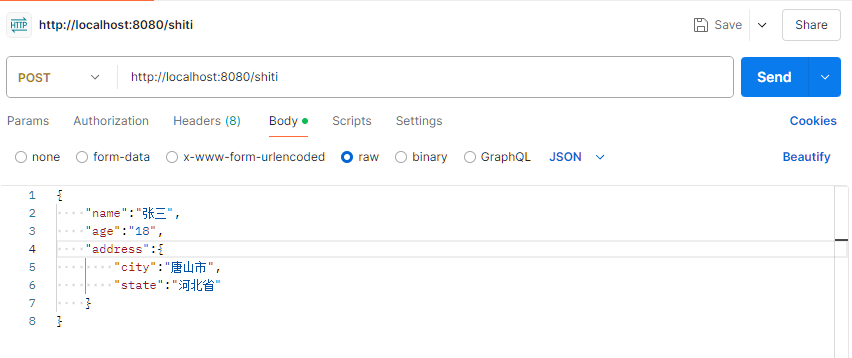
路径参数
通过请求URL直接传递的参数,使用{...}来表示该路径的参数,需要使用@PathVariavle获取路径参数
xxxxxxxxxx("/getPath/{p}")public String path( String p) { System.out.println(p); return "ok";}xxxxxxxxxxhttp://localhost:8080/getPath/12
响应
HttpServletResponse
响应数据
@ResponseBody
位置:方法注解,类注解
位置:Controller方法/类上
作用:将方法返回值直接响应,如果返回值是实体对象、集合,将会转换为JSON格式响应
说明:@RestController=@Controller+@ResponseBody
xxxxxxxxxxpackage org.example.chuli;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;import java.util.ArrayList;public class xiangying {("/string")public String string1() {return "string";}("/class")public Address string2() {Address address = new Address();address.setState("河北省");address.setCity("唐山市");return address;}("/list")public ArrayList<String> list() {ArrayList<String> list = new ArrayList<>();list.add("string");list.add("string");list.add("string");list.add("string");return list;}}
分层解耦
三层架构
Controller:控制层,接受前端发送的请求,对请求进行处理,并响应数据
Service:业务逻辑层,处理具体的业务逻辑。
dao:数据访问层(Data Access Object)(持久层),负责数据访问操作,包括数据的增删改查
分层解耦
内聚:软件中各个功能模块内部的功能联系。
耦合:衡量软件中各个层、模块之间的依赖,关联程度。
软件设计原则:高内聚低耦合
将使用的对象放在容器中,模块需要使用时,从容器中得到
控制反转:IOC(Inversion Of Control)。对象的创建控制权由程序自身转移到外部容器。
依赖注入:DI(Dependency Injection)。容器为应用程序提供运行时,所需的外部资源
Bean对象:IOC容器中创建、管理的对象。
IOC&DI入门
在使用IOC的程序上加入注解:@Component 在使用IOC程序提供的资源上添加注解:@Autowired
xxxxxxxxxxpublic class fenceng { //在运行时,IOC容器会提供该类型的Bean对象 private String a;}
IOC详解
要把某个对象交给IOC容器管理,需要在对应的类上加入对应注解
| 注解 | 说明 | 位置 |
|---|---|---|
| @Component | 声明bean的基础注解 | 不属于以下三类使用此注解 |
| @Controller | @Component的衍生注解 | 标注在控制器类上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上 |
Bean组件扫描
前面四个注解标志的对象要想生效,还需要被组件扫描注解@ComponentScan扫描
@ComponentScan注解虽然没有显示配置,默认已经包含在启动类声明在@SpringBootApplication中
DI详解
由于@Autowired默认是按照类型进行注入的,如果存在多个相同类型的bean,就会报错
解决方案:使用以下注解解决
@Primary:需要哪个Bean生效,就在哪个Bean上面加上次注解
@Qualifier:在Autowired上面使用此注解(Qualifier(value))指定生效的bean。
@Resource:不使用Autowired注解,使用此注解指定生效的Bean(Resource(name="beanname"))
总结
xxxxxxxxxx@Autowired:默认按照类型自动装配。如果同类型的bean存在多个,可以使用以下三种解决方案@Primary@Autowired+@Qualifier("bean的名称")@Resource(name="bean的名称")
扩展:@Resource与@Autowired区别
@Autowired是spring框架提供的注解,而@Resource是JDK提供的注解。
@Autowired默认是按照类型注入,而@Resource默认是按照名称注入。
MySQL
MySQL相关笔记请参考本站mysql笔记
SpringBoot Mybatis
Mybatis简介
MyBatis 是一款优秀的持久层(数据访问层)框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
Mybatis入门
使用Mybatis操作数据库
创建SpringBoot工程,数据库表和实体类
引入Mybatis依赖,配置Mybatis
 在application.properties文件中配置数据库的连接信息
在application.properties文件中配置数据库的连接信息xxxxxxxxxxspring.datasource.url=jdbc:mysql://localhost:3306/mybatisspring.datasource.username=rootspring.datasource.password=123456定义一个持久层的接口,只需要定义接口,不需要重写实现类,在调用方法时
编写SQL语句 案例:使用Mybatis查用户表中的所有数据
xxxxxxxxxx//接口类package org.example.mybatis_demo;import org.apache.ibatis.annotations.Mapper;//在运行时会自动生成该接口的实现类,并交给IOC容器管理public interface usermapper {("select * from user")//指定操作和语句public List<user> selectAll();}xxxxxxxxxx//user类package org.example.mybatis_demo;public class user {private Integer id;private String name;private Integer age;public String gender;public user() {}public user(Integer id, String name, Integer age, String gender) {this.id = id;this.name = name;this.age = age;this.gender = gender;}public void setId(Integer id) {this.id = id;}public void setName(String name) {this.name = name;}public void setAge(Integer age) {this.age = age;}public void setGender(String gender) {this.gender = gender;}public String toString() {return "user{" +"id=" + id +", name='" + name + '\'' +", age=" + age +", gender='" + gender + '\'' +'}';}}xxxxxxxxxx//测试类private usermap userMapper;void testSelectAll() {List<User> users = userMapper.selectAll();assertNotNull(users);users.forEach(System.out::println);}
JDBC介绍
使用Java语言操作关系型数据库的一套API
原始的JDBC程序操作繁琐,浪费计算机性能和资源
在Mybatis中将数据库连接信息配置到了单独的配置文件中,查询的结果会自动进行封装,利用数据库连接池技术避免频繁的连接和释放
数据库连接池
数据库连接池是一个容器,负责分配,管理数据库连接。
它允许应用程序的重复使用一个现有的数据库连接,而不是重新建立一个新的连接。
释放闲置时间超过最大限制时间的连接,避免因没有释放连接而引起的数据库连接遗漏。
数据库连接池的优点
资源重用
提升系统的响应速度
避免数据库连接遗漏
lombok
lombok可以简化编写实体类的代码,使得代码更加简洁
lombok是一个实用的Java类库,能通过注解的形式自动生成构造器,getter/setter方法,equals,hashcode,toString等方法,并可以自动化生成日志,简化Java开发,提高效率
lombox提供的部分注解
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 为类自动生成易阅读的tostring方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字符串自动重写equals和hashcode方法 |
| @Data | 提供了综合的生成代码功能(@Getter/@Setter/@ToString@EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各种参数的构造器方法 |
引入lombok依赖
xxxxxxxxxx<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>provided</scope></dependency>之前的实体类,代码臃肿
xxxxxxxxxxpackage org.example.demo4;
public class User { private Integer id; private String name; private Integer age; private String gender;
public User() { }
public User(Integer id, String name, Integer age, String gender) { this.id = id; this.name = name; this.age = age; this.gender = gender; }
public Integer getId() { return id; }
public void setId(Integer id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public Integer getAge() { return age; }
public void setAge(Integer age) { this.age = age; }
public String getGender() { return gender; }
public void setGender(String gender) { this.gender = gender; }
public String toString() { return "User{" + "id=" + id + ", name='" + name + '\'' + ", age=" + age + ", gender='" + gender + '\'' + '}'; }}使用lombok简化的代码,简介,一目了然
xxxxxxxxxxpackage org.example.demo4;
import lombok.Data;
public class User { private Integer id; private String name; private Integer age; private String gender;
}
Mybatis增删改查
注释配置SQL
本操作用到的数据库信息
xxxxxxxxxx-- 部门管理create table dept( id int unsigned primary key auto_increment comment '主键ID', name varchar(10) not null unique comment '部门名称', create_time datetime not null comment '创建时间', update_time datetime not null comment '修改时间') comment '部门表';
insert into dept (id, name, create_time, update_time) values(1,'学工部',now(),now()),(2,'教研部',now(),now()),(3,'咨询部',now(),now()), (4,'就业部',now(),now()),(5,'人事部',now(),now());
-- 员工管理create table emp ( id int unsigned primary key auto_increment comment 'ID', username varchar(20) not null unique comment '用户名', password varchar(32) default '123456' comment '密码', name varchar(10) not null comment '姓名', gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女', image varchar(300) comment '图像', job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师', entrydate date comment '入职时间', dept_id int unsigned comment '部门ID', create_time datetime not null comment '创建时间', update_time datetime not null comment '修改时间') comment '员工表';
INSERT INTO emp (id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time) VALUES (1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()), (2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()), (3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()), (4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()), (5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()), (6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()), (7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()), (8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()), (9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()), (10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()), (11,'luzhangke','123456','鹿杖客',1,'11.jpg',5,'2007-02-01',3,now(),now()), (12,'hebiweng','123456','鹤笔翁',1,'12.jpg',5,'2008-08-18',3,now(),now()), (13,'fangdongbai','123456','方东白',1,'13.jpg',5,'2012-11-01',3,now(),now()), (14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()), (15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()), (16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2010-01-01',2,now(),now()), (17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());参数占位符
#{...}
执行SQL时,会将#{...}替换为?,生成预编译的SQL,会自动设置参数值
使用时机:参数传递,都是用#{...}
${...}
拼接SQL,直接将参数拼接在SQL语句中,存在SQL注入问题,有安全漏洞
使用时机:对表名,列表进行动态设置时使用,使用场景少
查询
根据主键ID查询,用于页面回显
xxxxxxxxxx//查询指定信息("select * from emp where id=#{ids}")User shows(int ids);xxxxxxxxxxvoid testselect(){User a1 = userMapper.shows(11);System.out.printf(a1.toString());}结果发现,创建时间,修改时间未自动封装
xxxxxxxxxx(id=11, userName=luzhangke, passWord=123456, name=鹿杖客, gender=1, image=11.jpg, job=5, entryDate=2007-02-01, deptId=0, createTime=null, updateTime=null)2024-08-15T11:57:13.966+08:00数据封装
实体类和数据库表查询返回字段一致,Mybatis会自动封装。
如果实体类和数据库表查询返回字段不一致,不会自动封装。
方案1:给字段起别名,让别名与实体类的属性一致
xxxxxxxxxx//查询指定信息("select ID, USERNAME, PASSWORD, NAME, GENDER, IMAGE, JOB, ENTRYDATE, DEPT_ID, CREATE_TIME createTime, UPDATE_TIME updateTime from emp where id=#{ids}")User shows(int ids);方案2:使用@Results,@Result注解手动映射封装
xxxxxxxxxx//查询指定信息({(column = "dept_id",property = "deptId"),//column = "映射的字段",property = "映射到。。。"(column = "create_time",property = "createTime"),(column = "update_time",property = "updateTime")})//一个Result注解映射一个字段("select * from emp where id=#{ids}")User shows(int ids);⭐方案3:开启Mybaits驼峰命名自动映射 前提:字段名必须是下划线命名,字段名必须严格遵循驼峰命名
xxxxxxxxxx//在属性配置文件中开启mybatis.configuration.map-underscore-to-camel-case=true条件查询
xxxxxxxxxx//条件查询接口("select * from emp where name like '%${name}%' and gender =#{gender} and entrydate between #{begin} and #{end}")List<User> showsome(String name, short gender, LocalDate begin, LocalDate end);//name like '%${name}%'可以使用字符串拼接("select * from emp where name like concat('%',#{name},'%') and gender =#{gender} and entrydate between #{begin} and #{end}")xxxxxxxxxx//测试方法void testSelectsome() {List<User> users = userMapper.showsome("张",(short) 1,LocalDate.of(2010,1,1),LocalDate.of(2015,1,1));users.forEach(System.out::println);}
新增
xxxxxxxxxx//新增数据方法("INSERT INTO emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) " +"VALUES (#{userName},#{name},#{gender},#{image},#{job},#{entryDate},#{deptId},#{createTime},#{updateTime})")void insert(User user);xxxxxxxxxx//测试方法void testinsert(){User u =new User();u.setUserName("zhangsan");u.setName("张三");u.setGender((short) 1);u.setImage("1.png");u.setJob((short) 1);u.setEntryDate(LocalDate.of(2021,3,3));u.setDeptId((short) 1);u.setCreateTime(LocalDateTime.now());u.setUpdateTime(LocalDateTime.now());userMapper.insert(u);}新增数据后返回主键
xxxxxxxxxx(keyProperty = "id",useGeneratedKeys = true)//使用Options声明,插入完成后会将ID返回到对象的ID属性中("INSERT INTO emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) " +"VALUES (#{userName},#{name},#{gender},#{image},#{job},#{entryDate},#{deptId},#{createTime},#{updateTime})")void insert(User user);修改
xxxxxxxxxx//更新接口("UPDATE emp set username=#{userName},name=#{name},gender=#{gender},image=#{image},job=#{job},entrydate=#{entryDate},dept_id=#{deptId},update_time=#{updateTime} where id =#{id}")void update(User user);xxxxxxxxxx//测试方法void testinsert(){User u =new User();u.setUserName("zhangsanfeng1");u.setName("张三风1");u.setGender((short) 1);u.setImage("1.png");u.setJob((short) 1);u.setEntryDate(LocalDate.of(2021,3,3));u.setDeptId((short) 1);u.setCreateTime(LocalDateTime.now());u.setUpdateTime(LocalDateTime.now());userMapper.insert(u);System.out.printf(u.getId().toString());}删除
根据主键ID删除
xxxxxxxxxx("delete from emp where id =#{id}")//使用#{}作为占位符,获取传入的IDvoid deleteById(Integer id);//此操作有返回值,返回值为影响的数据行数//测试程序void testdeleteById() {userMapper.deleteById(17);}根据主键ID批量删除 参考动态SQL的foreach
XML文件配置SQL语句
规范
XML映射文件的名称要与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
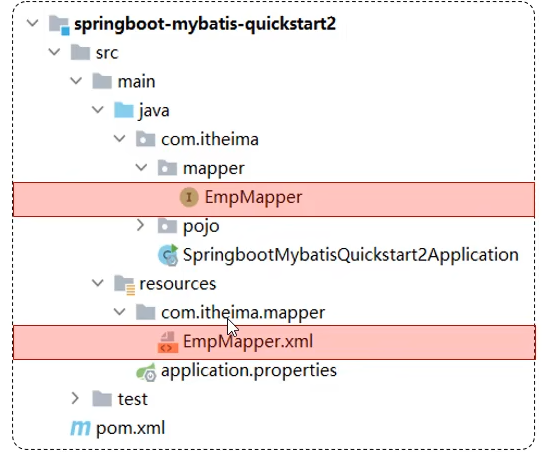
XML映射文件的namespace属性为Mapper接口全类名一致
XML文件中的SQL语句的id与Mapper接口中的方法名一致,并保持返回类型一致
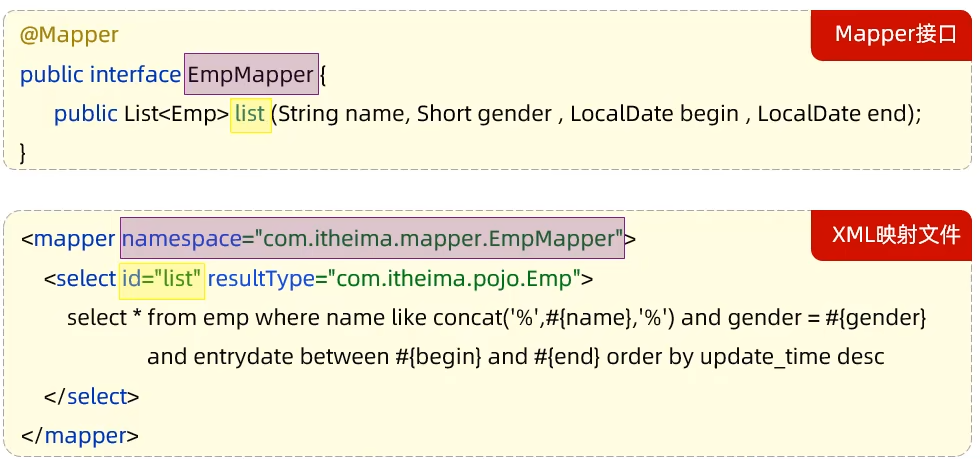
配置内容
xxxxxxxxxx<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="org.mybatis.example.BlogMapper"><select id="selectBlog" resultType="Blog">select * from Blog where id = #{id}</select></mapper>
这个插件可以快速定位接口与sql语句直接的关系
点击小鸟可完成快速跳转
使用注解来映射简单语句会使代码显得更加简洁,但对于稍微复杂一点的语句,Java 注解不仅力不从心,还会让你本就复杂的 SQL 语句更加混乱不堪。 因此,如果你需要做一些很复杂的操作,最好用 XML 来映射语句。
选择何种方式来配置映射,以及认为是否应该要统一映射语句定义的形式,完全取决于你和你的团队。 换句话说,永远不要拘泥于一种方式,你可以很轻松的在基于注解和 XML 的语句映射方式间自由移植和切换。
Mybatis动态SQL
动态SQL是随着用户输入或外部条件的变化而变化的SQL语句
<if>
xxxxxxxxxx<mapper namespace="org.example.demo4.usermap"> <select id="showsome" resultType="org.example.demo4.User"> select * from emp <where>//where标签可以自动去除语句中多余的and <if test="name!=null"> name like concat('%',#{name},'%') </if> <if test="gender!=null"> and gender =#{gender} </if> <if test="begin!=null and end!=null "> and entrydate between #{begin} and #{end} </if> </where> </select></mapper>xxxxxxxxxx<where></where>//where标签可以自动去除语句中多余的and、or<set></set>//可以自动去除update语句中多余的逗号
<foreach>
foreach标签属性介绍
collection:遍历的集合
item:遍历出的元素
separator:分隔符
open:遍历之前拼接的符号
close:遍历最后拼接的符号
需求:批量删除数据
xxxxxxxxxx//接口void deletesome(List<Integer> ids1);xxxxxxxxxx//xml删除语句<delete id="deletesome"> delete from emp where id in <foreach collection="ids1" item="id" separator="," open="(" close=")">#{id}</foreach></delete>xxxxxxxxxx//测试方法void delectsometest() { List<Integer> ids = Arrays.asList(16, 18, 21); userMapper.deletesome(ids);}
<sql>&&<include>
<sql>用于定义可重用的SQL语句片段
<include>:通过refid属性,引入SQL片段
xxxxxxxxxx<sql id="sel"> select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp</sql><select id="selectAll" resultType="org.example.demo4.User"> <include refid="sel"></include></select>
案例:教学辅助系统
开发学习系统的部门管理和员工管理模块
体会前后端交互方式
准备
准备数据库表
引入相关依赖(web,mybatis,mysql驱动,lombok)
配置application.properties中引入mybatis的配置信息,准备对应的实体类
三层架构(mapper,server,controller)的基础结构
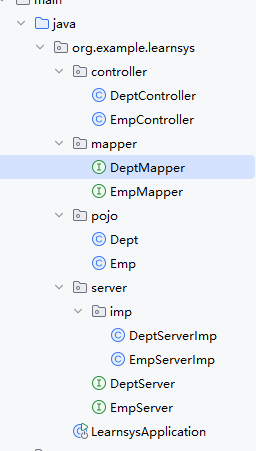
部门管理
查询部门列表
删除部门
新增部门
修改部门
前后端联调
员工管理
查询员工列表
删除员工
新增员工
修改员工
分页查询插件:PageHelper
xxxxxxxxxx//引入依赖<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><version>2.1.0</version></dependency>
文件上传
指的是将本地图片,视频,音频等文件上传到服务器,供其他用户浏览或下载的过程
文件上传表单的三要素

xxxxxxxxxx<form action="www.baidu.com/upload" method="post" enctype="multipart/form-data"> <input type="text" name="username" id=""> <input type="text" name="passworld" id=""> <input type="file" name="files" id=""> <input type="submit" value=""></form>
服务端接收数据
普通数据依然正常接收,文件使用 MultipartFile 接收

存储方式
本地存储
将接受的文件转存到服务器磁盘
在MultipartFile中提供了一个transferTo方法,可以将接收到的文件转存到指定的磁盘目录中 在获取原始文件名时,可以使用MultipartFile中提供的getOriginalFilename()方法获取
为了防止文件名重复问题,可以使用UUID解决
上传文件的默认最大为1MB,可以通过配置属性文件修改允许上传的最大文件大小
xxxxxxxxxx#单个文件限制大小spring.servlet.multipart.max-file-size=10MB#单个请求最大文件大小spring.servlet.multipart.max-request-size=100MB
云存储
使用云服务提供商,提供的对象存储服务OSS
准备
注册云服务账号
开通对象存储服务OSS
创建存储空间
获取密钥
参考官网文档进行开发
配置文件
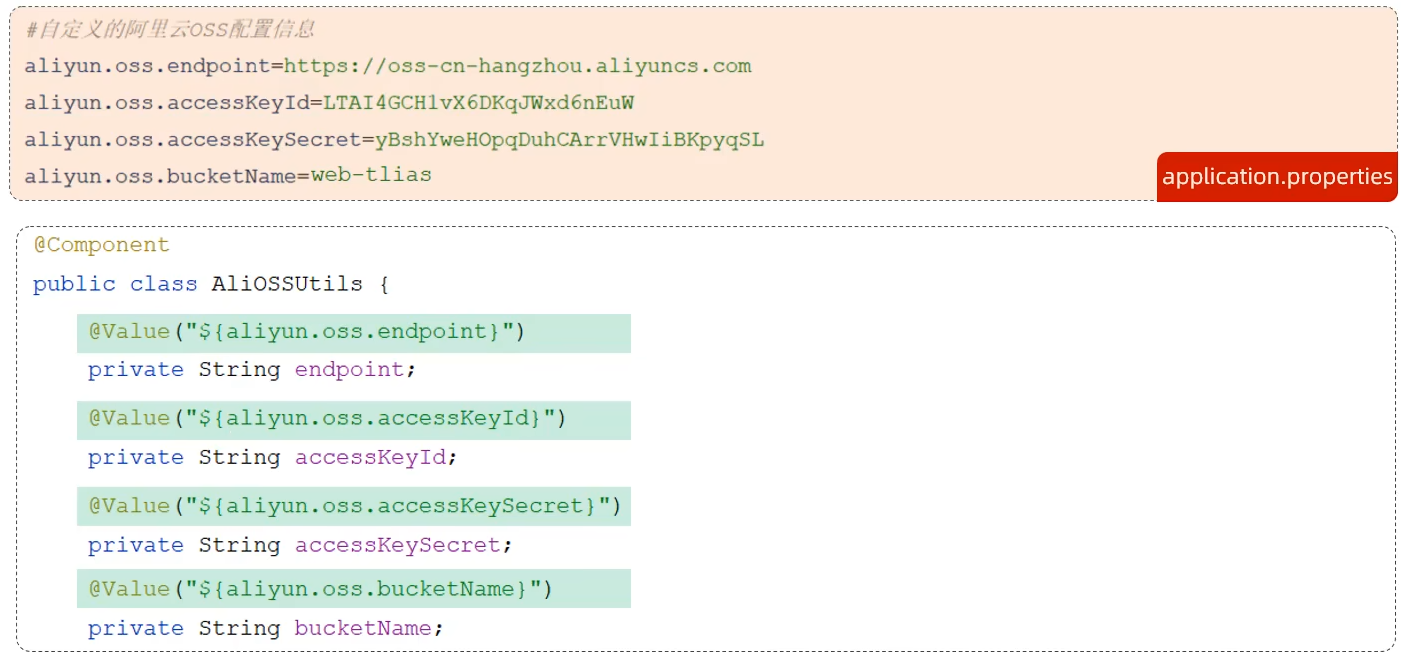
参数配置化
可以将阿里云的配置信息配置到SpringBoot的配置文件中,通过外部配置的属性注入方式添加属性
用法@Value("${配置文件中的KEY}")
yml配置文件
后缀名可以是yml,也可以是yaml
书写格式KEU:VALUE,并按照层级进行书写
xxxxxxxxxxserve address:127.0.0.1 port:8080yml配置基本语法
大小写敏感
数值前面必须加空格,作为分隔符
使用缩进表示层级关系,缩进是不允许使用tab,要使用空格(在IDEA中会自动将TAB转化为空格,可忽略)
缩进空格数目不重要,相同层级缩进数量相同即可
#表示注释
xxxxxxxxxx#定义对象/Map集合user nametom age10 addressshanghai#定义数组/List/Set集合hobbyjavagamesport
@ConfigurationProperties
这个注解可以将配置文件中的数据注入到对象中,要求配置文件的属性名要和对象的属性名相同才能完成自动注入,再将该对象交给IOC容器管理即可,使用时再将此对象对象进行注入。

登录功能
基础登录
逻辑:使用输入的用户名和密码在数据库中查找,查找到结果即为登录成功,反之认为登录失败
xxxxxxxxxx//colltrollerpackage org.example.learnsys.controller;
import lombok.extern.slf4j.Slf4j;import org.example.learnsys.pojo.Emp;import org.example.learnsys.pojo.Result;import org.example.learnsys.server.imp.LoginServerImp;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestBody;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;
public class LoginColltroller { private LoginServerImp loginServerImp; ("/login") public Result login( Emp emp){ Emp a = loginServerImp.LoginCheck(emp); return a !=null? Result.success():Result.error("用户名或密码错误");
}}
xxxxxxxxxx//serverpackage org.example.learnsys.server.imp;
import org.example.learnsys.mapper.LoginMapper;import org.example.learnsys.pojo.Emp;import org.example.learnsys.server.LoginServer;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;
public class LoginServerImp implements LoginServer { private LoginMapper loginMapper; public Emp LoginCheck(Emp emp) { return loginMapper.loginCount(emp); }}xxxxxxxxxxpackage org.example.learnsys.server;
import org.example.learnsys.pojo.Emp;
public interface LoginServer { Emp LoginCheck(Emp emp);}
xxxxxxxxxx//Mapperpackage org.example.learnsys.mapper;
import org.apache.ibatis.annotations.Mapper;import org.apache.ibatis.annotations.Select;import org.example.learnsys.pojo.Emp;
()public interface LoginMapper { ("select * from emp where username=#{username} && password = #{password}") Emp loginCount(Emp emp);}
登录校验
会话技术
会话:用户打开浏览器,访问web服务器的资源,会话建立,直到一方断开连接,会话结束,在一次会话中可以包含多次请求和响应。
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自同一个浏览器,以便在同一次会话的多次请求间共享数据。
会话跟踪方案
客户端会话跟踪技术:cookie
服务端会话跟踪技术:Session
令牌技术
会话跟踪技术对比
cookie 登录完成后,返回cookie保存在浏览器,之后浏览器发出请求时,会携带此Cookie Cookie请求头 set-cookie响应头
优点: HTTP协议中支持的技术
缺点: 移动端无法使用cookie 不安全,用户可以自己禁用cookie
cookie不能跨域
Session 将会话生成的Cookie存储在服务器端 优点:存储在服务器端,更安全 缺点: 集群服务器下无法使用 Cookie的所有缺点
令牌技术 服务端生成一个令牌相应给浏览器,浏览器将其存储起来,客户端服务端交互时携带此令牌
优点: 即支持PC端,又支持移动端
解决集群部署下的认证问题 减轻服务端的存储压力
缺点:需要自己去实现
JWT令牌 介绍
什么是 JSON Web 令牌?
JSON Web 令牌 (JWT) 是一种开放标准 (RFC 7519),它定义了一种紧凑且自包含的方式,用于将信息作为 JSON 对象在各方之间安全地传输。此信息是经过数字签名的,因此可以验证和信任。可以使用密钥(使用 HMAC 算法)或使用 RSA 或 ECDSA 的公钥/私钥对对 JWT 进行签名。
尽管 JWT 可以加密以在各方之间提供机密性,但我们将重点介绍签名令牌。签名令牌可以验证其中包含的声明的完整性,而加密令牌则对其他方隐藏这些声明。当使用公钥/私钥对令牌进行签名时,签名还会证明只有持有私钥的一方是签署私钥的一方。
何时应使用 JSON Web 令牌?
以下是 JSON Web 令牌有用的一些情况:
授权:这是使用 JWT 的最常见场景。用户登录后,每个后续请求都将包含 JWT,允许用户访问该令牌允许的路由、服务和资源。单点登录是当今广泛使用 JWT 的一项功能,因为它的开销小,并且能够轻松地跨不同域使用。
信息交换:JSON Web 令牌是在各方之间安全地传输信息的好方法。由于 JWT 可以签名(例如,使用公钥/私钥对),因此您可以确保发件人是他们所声称的身份。此外,由于签名是使用标头和有效负载计算的,因此您还可以验证内容是否未被篡改。
什么是 JSON Web 令牌结构?
在其紧凑形式中,JSON Web 令牌由三个部分组成,由点 () 分隔,它们是:
.页眉,头部:记录令牌类型,签名算法等
有效载荷:携带一些默认信息,自定义信息等
签名:防止被ToKen被篡改,确保安全性,将header,payload,并加入指定密钥,通过指定签名算法计算而来
使用场景
登录认证 登陆成功后,生成JWT令牌 后续请求中,都要携带JWT令牌,系统在每次请求处理之前先校验令牌,通过后在进行业务逻辑的执行
生成JWT令牌
在POM文件中引入JWT依赖
xxxxxxxxxx<dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.12.6</version></dependency>生成JWT令牌
xxxxxxxxxxpublic void jwt1tes1(){Map<String, Object> claims = new HashMap<>();claims.put("USR", "admin");claims.put("PWD", "12312");// JwtBuilder J =Jwts.builder().signWith(SignatureAlgorithm.HS256,"secretkey")//设置签名算法// .setClaims(claims)//自定义载荷// .setExpiration(new Date(System.currentTimeMillis()+3600*1000));//设置令牌有效期String J =Jwts.builder().signWith(SignatureAlgorithm.HS256, "sadassadassadassadassadassadassadassadassadas").setClaims(claims).setExpiration(new Date(System.currentTimeMillis()+3600*1000)).compact();System.out.printf(J);}在java中解析令牌 java17及之后要在.setSigningKey()后面加上.build()
xxxxxxxxxxpublic void jiexi(){System.out.printf("%s", Jwts.parser().setSigningKey("sadassadassadassadassadassadassadassadassadas").build().parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJVU1IiOiJhZG1pbiIsIlBXRCI6IjEyMzEyIiwiZXhwIjoxNzI1MTE0MzE1fQ.WwnNl-TTdOxrmctOw5svw-NDDYHAJ64OMCL0s3ciwss").getBody());}登录下发令牌 令牌生成:用户完成登陆后,服务器下发令牌给前端 令牌校验:请求到达服务端后,对令牌进行统一拦截和校验
过滤器Filter 过滤器可以把对资源的请求拦截下来,实现一些特殊的功能 过滤器一般完成一些通用的操作,如:登录校验,统一编码处理,敏感字符处理等
快速入门:
定义过滤器:定义一个类,实现Filter接口,并重写所有方法。
xxxxxxxxxxpackage org.example.learnsys.server.imp;import jakarta.servlet.*;import jakarta.servlet.annotation.WebFilter;import java.io.IOException;(urlPatterns = "/*")public class Filterevery implements Filter {public void init(FilterConfig filterConfig) throws ServletException {// Filter.super.init(filterConfig);//过滤器初始化,只会执行一次System.out.println("过滤器初始化成功");}public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {//过滤器逻辑filterChain.doFilter(servletRequest, servletResponse);//放行System.out.println("过滤器拦截到了请求");}public void destroy() {// Filter.super.destroy();//过滤器释放,只会执行一次System.out.println("过滤器销毁成功");}}配置过滤器:Filter类上加上@WebFilter注解,配置拦截资源的路径,引导类上加上@ServletComponentScan开启Servlet组件支持。
xxxxxxxxxxpublic class LearnsysApplication {public static void main(String[] args) {SpringApplication.run(LearnsysApplication.class, args);}}
拦截路径配置
xxxxxxxxxx@WebFilter(urlPatterns = "/*")// /*代表拦截所有路径拦截路径 urlPatterns 解释 拦截具体路径 /login 只有访问login路径时,才会被拦截 目录拦截 /name/* 访问/name路径下的所有资源都会被拦截 拦截所有 /* 访问所有资源都会被拦截 过滤器链 一个web应用中,可以配置多个过滤器,这多个过滤器就形成了一个过滤器链。 过滤器的优先级是按照过滤器类名自然排序的。类名排的越靠前,优先级越高。
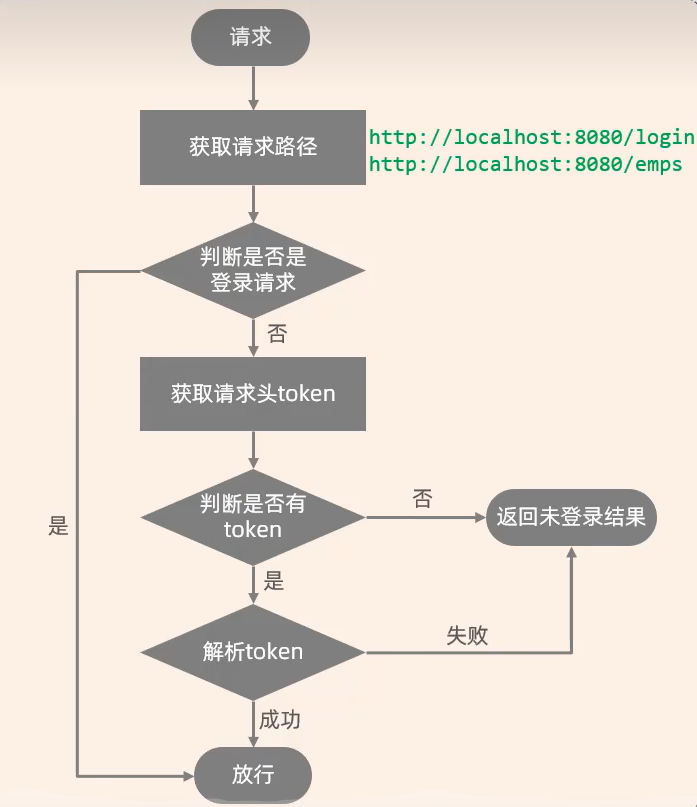
使用过滤器进行登陆校验。校验令牌的有效性 实现步骤:
获取请求URL
判断URL中是否包含login,如果包含,说明是登陆操作,放行
获取请求头中的token
判断令牌是否存在,如果不存在,返回未登录的错误信息
解析token,如果解析失败,返回未登录的错误信息
放行
拦截器Interceptor 介绍 Interceptor是一种动态拦截方法调用的机制,类似过滤器。是spring框架中提供的,用来动态拦截控制器方法的执行 作用
日志记录:记录请求信息的日志,以便进行信息监控、信息统计、计算 PV(Page View)等;
权限检查:如登录检测,进入处理器检测是否登录;
性能监控:通过拦截器在进入处理器之前记录开始时间,在处理完后记录结束时间,从而得到该请求的处理时间。(反向代理,如 Apache 也可以自动记录)
通用行为:读取 Cookie 得到用户信息并将用户对象放入请求,从而方便后续流程使用,还有如提取 Locale、Theme 信息等,只要是多个处理器都需要的即可使用拦截器实现。
使用步骤
定义拦截器,让其实现HandlerInterceptor接口,并重写以下方法
preHandler(HttpServletRequest request, HttpServletResponse response, Object handler)方法在请求处理之前被调用。该方法在 Interceptor 类中最先执行,用来进行一些前置初始化操作或是对当前请求做预处理,也可以进行一些判断来决定请求是否要继续进行下去。该方法的返回至是 Boolean 类型,当它返回 false 时,表示请求结束,后续的 Interceptor 和 Controller 都不会再执行;当它返回为 true 时会继续调用下一个 Interceptor 的 preHandle 方法,如果已经是最后一个 Interceptor 的时候就会调用当前请求的 Controller 方法。postHandler(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView)方法在当前请求处理完成之后,也就是 Controller 方法调用之后执行,但是它会在 DispatcherServlet 进行视图返回渲染之前被调用,所以我们可以在这个方法中对 Controller 处理之后的 ModelAndView 对象进行操作。afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handle, Exception ex)方法需要在当前对应的 Interceptor 类的 postHandler 方法返回值为 true 时才会执行。顾名思义,该方法将在整个请求结束之后,也就是在 DispatcherServlet 渲染了对应的视图之后执行。此方法主要用来进行资源清理。xxxxxxxxxxpackage org.example.learnsys.interceptor;import jakarta.servlet.http.HttpServletRequest;import jakarta.servlet.http.HttpServletResponse;import org.springframework.stereotype.Component;import org.springframework.web.servlet.HandlerInterceptor;import org.springframework.web.servlet.ModelAndView;public class lanjieqiinterceptor implements HandlerInterceptor {public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {return true;}public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {System.out.println("拦截到了请求");HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);}public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {HandlerInterceptor.super.afterCompletion(request, response, handler, ex);}}注册拦截器 新建一个类,添加
@Configuration注释,实现WebMvcConfigurer接口,重写addInterceptors方法。xxxxxxxxxxpackage org.example.learnsys.config;import org.example.learnsys.interceptor.lanjieqiinterceptor;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Configuration;import org.springframework.web.servlet.HandlerInterceptor;import org.springframework.web.servlet.config.annotation.InterceptorRegistry;import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;public class lanjiqiconfig implements WebMvcConfigurer {private lanjieqiinterceptor lanjieqiinterceptor;public void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor( lanjieqiinterceptor).addPathPatterns("/**");// 配置拦截器拦截路径}}
拦截路径配置介绍
xxxxxxxxxxregistry.addInterceptor(new AdminInterceptor()).addPathPatterns("/admin/*").excludePathPatterns("/admin/oldLogin");addPathPatterns("/admin/*"):配置需要拦截的路径
拦截路径 含义 示例 /* 一级路径 能匹配/depts,/emps,/login,不能匹配/depts/1 /** 任意级路径 能匹配/depts,/depts/1,/depts/1/2 /depts/* /depts下的一级路径 能匹配/depts/1,不能匹配/depts/1/2,/depts /depts/** depts下的任意级路径 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 excludePathPatterns("/admin/oldLogin"):配置不需要进行拦截的路径
过滤器 VS 拦截器
过滤器和拦截器的区别主要体现在以下 5 点:
出身不同; 过滤器来自于 Servlet,而拦截器来自于 Spring 框架
触发时机不同; 请求的执行顺序是:请求进入容器 > 进入过滤器 > 进入 Servlet > 进入拦截器 > 执行控制器(Controller)
实现不同; 过滤器是基于方法回调实现的,拦截器是基于动态代理(底层是反射)实现的
支持的项目类型不同; 过滤器是 Servlet 规范中定义的,所以过滤器要依赖 Servlet 容器,它只能用在 Web 项目中;而拦截器是 Spring 中的一个组件,因此拦截器既可以用在 Web 项目中,同时还可以用在 Application 或 Swing 程序中。
使用的场景不同。
因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:登录判断、权限判断、日志记录等业务。 而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、字符集编码设置、响应数据压缩等功能。
总结
过滤器和拦截器都是基于 AOP 思想实现的,用来处理某个统一的功能的,但二者又有 5 点不同:出身不同、触发时机不同、实现不同、支持的项目类型不同以及使用的场景不同。过滤器通常是用来进行全局过滤的,而拦截器是用来实现某项业务拦截的。
异常处理
在项目开发中,不可避免的会出现很多异常,出现异常后,返回的结果可能不是API文档中指定的返回数据格式,导致前端页面无法正常解析。
处理方法:全局异常处理器
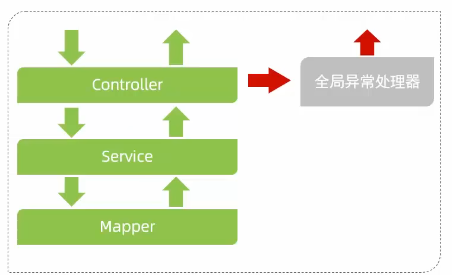
xxxxxxxxxxpublic class GlobalExceptionHandler { (Exception.class) public Result ex(Exception ex){ ex.printStackTrace(); return Result.error(”对不起,操作失败,请联系管理员"); }}
Spring事务管理
事务:是一组操作的集合,它是不可分割的一个工作单位,这些操作要么同时成功,要么同时失败。
需求:删除管理系统中的部门信息时,同时删除该部门下的所有员工
xxxxxxxxxxpublic class DeptServiceImpl implements DeptService{ private DeptMapper deptMapper; private EmpMapper empMapper; public void delete(Integer id){ //1,删除部门 deptMapper.delete(id); inti=1/0;//模拟抛出异常 //2.根据部门id,删除部门下的员工信息 empMapper.deleteByDeptId(id); }}xxxxxxxxxx/根据部门ID,,删除该部门下的员工数据@Delete("delete from emp where dept_id = #{deptId)"void deleteByDeptId(Integer deptId);
以上代码出现异常后,导致部门信息被删除,但是员工却未被删除,造成数据不一致,不完整问题
spring事务管理
xxxxxxxxxx注解:@Transactional位置:业务层的方法上,类上,接口上作用:将当前方法交给spring进行事务管理,方法执行前,开启事务;成功执行完毕,提交事务;出现异常,回滚事务
xxxxxxxxxxpublic void delete(Integer id){ //1,删除部门 deptMapper.delete(id) ; int i=1/0;//模拟抛出异常 //2,根据部门id,删除部门下的员工信息 empMapper.deleteByDeptId(id);}
@Transactional注解的属性
rollbackFor 默认情况下,只有出现RuntimeException才回滚异常。rollbackFor属性用于控制出现何种异常类型,回滚事务。
xxxxxxxxxx@Transactional(rollbackFor = Exception.class)// 出现所有异常都会进行回滚propagation 事务传播行为:指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。
Propagation是个枚举,有7种值,如下:
事务传播行为类型 说明 REQUIRED 如果当前事务管理器中没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择,是默认的传播行为。 SUPPORTS 支持当前事务,如果当前事务管理器中没有事务,就以非事务方式执行。 MANDATORY 使用当前的事务,如果当前事务管理器中没有事务,就抛出异常。 REQUIRES_NEW 新建事务,如果当前事务管理器中存在事务,把当前事务挂起,然后会新建一个事务。 NOT_SUPPORTED 以非事务方式执行操作,如果当前事务管理器中存在事务,就把当前事务挂起。 NEVER 以非事务方式执行,如果当前事务管理器中存在事务,则抛出异常。 NESTED 如果当前事务管理器中存在事务,则在嵌套事务内执行;如果当前事务管理器中没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 
需求:解散部门时,无论是成功还是失败,都要记录操作日志。 步骤: ①.解散部门:删除部门、删除部门下的员工 ②.记录日志到数据库表中
AOP
AOP概述
面向切面编程(AOP)是一种编程范式,它允许开发者将横切关注点(如日志、事务管理等)与业务逻辑分离,从而提高模块化。AOP 通过在运行时动态地将代码插入到特定的类方法或位置上,实现了对这些横切关注点的集中管理。这种方法不仅降低了模块间的耦合度,还使得代码更易于扩展和维护。
动态代理是面向切面编程最主流的实现。而SpringAOP是Spring框架的高级技术,旨在管理bean对象的过程中,主要通过底层的动态代理机制,对特定的方法进行编程。
AOP的优点
提高代码的模块化:
通过将与核心业务逻辑无关的代码(如日志、性能监控、事务处理等)提取到“切面”中,可以使得业务逻辑更加简洁和清晰,减少代码冗余。
这种方式使得“横切关注点”与业务逻辑代码分离,从而避免了在每个业务方法中都编写相同的辅助代码。
解耦代码:
AOP 可以将横切关注点从核心业务逻辑中解耦,减少了代码的耦合性。
比如,事务管理、缓存、日志等功能,AOP 可以在不修改现有业务代码的情况下,插入相关功能,提高了代码的灵活性和可维护性。
增强代码重用性:
由于切面是独立于业务逻辑的,可以在多个地方复用相同的切面代码。例如,统一的日志记录或事务管理功能,可以应用于多个模块或服务,而不需要重复编写。
减少代码重复:
AOP 通过切面将公共功能(例如日志记录、性能监控、认证和授权等)集中管理,避免了在多个类或方法中重复编写相同的代码。
这种方式使得系统的维护更加容易,减少了冗余代码。
提高开发效率:
开发人员可以将重点集中在业务逻辑的实现上,而不需要担心如何处理诸如日志、事务管理等横切关注点。
因为这些横切关注点已经被封装到切面中,开发人员可以直接使用 AOP 提供的功能,而无需手动添加重复的代码。
增强代码的可测试性:
通过将切面和核心业务逻辑分离,可以更容易地进行单元测试。业务逻辑可以单独进行测试,而切面功能也可以单独进行测试,提升了测试的粒度和独立性。
动态代理和方法拦截:
AOP 通过代理(通常是动态代理)对方法的执行进行拦截,提供了比传统的硬编码拦截更加灵活和动态的方式。
开发人员无需修改原始代码就能为现有方法添加额外的功能。
AOP的应用场景
日志记录:
在方法执行前后自动记录日志,特别适用于调试和监控。
事务管理:
使用 AOP 可以在方法调用前后自动进行事务的开启、提交和回滚。
安全控制:
可以在方法执行前检查用户权限,决定是否允许执行该方法。
性能监控:
可以对方法执行的时间进行计时,监控方法的性能。
缓存:
在方法执行前检查是否有缓存的结果,如果有直接返回缓存结果,否则执行方法并缓存结果。
AOP入门
导入AOP依赖
xxxxxxxxxx<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> <version>3.4.2</version></dependency>编写AOP程序
需求:记录每个业务操作的执行时间,优化项目
xxxxxxxxxxpackage org.example.learnsys.aop;
import lombok.extern.slf4j.Slf4j;import org.aspectj.lang.ProceedingJoinPoint;import org.aspectj.lang.annotation.Around;import org.aspectj.lang.annotation.Aspect;import org.springframework.stereotype.Component;
// 添加注解public class timeAspect { // 针对某些特定的业务方法进行测试(如controller),使用 @Around注解设定需要测试的业务 ("execution(* org.example.learnsys.controller.*.*(..))") public Object timeAspect(ProceedingJoinPoint pjp) throws Throwable { // 获取方法开始时的时间 long startTime = System.currentTimeMillis(); // 运行原始方法 Object result = pjp.proceed(); // 方法运行结束,获取时间,计算耗时 long endTime = System.currentTimeMillis(); log.info(pjp.getSignature()+"process time: {} ms", endTime - startTime); return result; }}
AOP核心概念
切面(Aspect)
切面是 AOP 的核心概念之一,它是横切关注点的模块化表示。切面定义了一个跨越多个类或方法的关注点,例如事务管理、日志记录、缓存等。
切面通过
@Aspect注解标识(在 Spring AOP 中),它封装了具体的横切功能。
示例:
xxxxxxxxxxjava复制编辑@Aspectpublic class LoggingAspect {// 切面的定义,通常包含切入点和通知}
连接点(Join Point)
连接点是程序执行过程中明确的点,AOP 会在这些点进行“切入”并应用通知(如方法调用)。在 Java 中,连接点通常指方法的执行过程。
在 Spring AOP 中,连接点通常是方法执行,但也可以是字段的访问等。
示例:
方法执行时(例如,执行某个方法时),它是一个连接点。
切入点(Pointcut)
切入点定义了哪些连接点会被拦截。通过切入点表达式,AOP 决定在哪些方法执行时应用特定的切面逻辑。切入点通常用
execution表达式来定义。切入点是指通知应用的具体位置,它通过匹配连接点来决定何时执行某个通知。
示例:
xxxxxxxxxxjava复制编辑@Pointcut("execution(* org.example.learnsys.controller.*.*(..))")public void controllerMethods() {}
通知(Advice)
通知是在切入点处执行的动作,具体指的是在连接点执行时,AOP 框架所执行的代码。通知有多种类型,根据执行时机的不同可以分为以下几种:
前置通知(Before): 在方法执行前执行。
后置通知(After): 在方法执行后执行,不论方法是否抛出异常。
返回通知(After Returning): 在方法成功执行后执行,获取方法的返回值。
异常通知(After Throwing): 在方法抛出异常后执行。
环绕通知(Around): 在方法执行前后都可以执行,可以决定是否执行目标方法。
示例:
xxxxxxxxxxjava复制编辑@Before("execution(* org.example.learnsys.controller.*.*(..))")public void logBefore(JoinPoint joinPoint) {System.out.println("Before executing method: " + joinPoint.getSignature().getName());}
织入(Weaving)
织入是将切面应用到目标对象的过程。织入可以发生在编译时、类加载时或运行时。
在 Spring AOP 中,织入是通过代理机制实现的,通常是在运行时将切面织入到目标对象中。
目标对象(Target Object)
目标对象是被 AOP 代理的对象,通常是我们在程序中定义的类。目标对象通常包含业务逻辑,而 AOP 的功能(切面)则被应用到目标对象的方法上。
在 Spring AOP 中,目标对象是我们想要应用切面的 Spring Bean。
代理(Proxy)
代理是 AOP 中用于将切面应用到目标对象的机制。通过代理对象,AOP 框架能够拦截对目标对象方法的调用,并应用通知。
Spring AOP 使用动态代理(JDK 动态代理或 CGLIB 代理)来实现 AOP 功能。
JDK 动态代理: 只适用于接口的代理,代理对象实现目标对象的接口。
CGLIB 动态代理: 适用于没有接口的类,代理对象是目标类的子类。
引入(Introduction)
引入是 AOP 允许向目标对象添加新的方法或属性。通过引入,可以给目标对象动态地添加额外的功能,而不需要修改目标类的代码。
在 Spring AOP 中,
@DeclareParents注解用于引入新功能。
AOP 执行流程
客户端调用目标对象的方法。
AOP 代理对象拦截方法调用(根据切入点匹配)。
执行通知(如前置通知、环绕通知等)。
调用目标方法(如果是环绕通知,可以控制是否调用)。
方法执行完后,执行相应的后置通知、返回通知或异常通知。

通知
通知类型
通知有多种类型,根据执行时机的不同可以分为以下几种:
前置通知(Before): 在方法执行前执行。
后置通知(After): 在方法执行后执行,不论方法是否抛出异常。
返回通知(After Returning): 在方法成功执行后执行,获取方法的返回值。
异常通知(After Throwing): 在方法抛出异常后执行。
环绕通知(Around): 在方法执行前后都可以执行,可以决定是否执行目标方法。
@Around环绕通知需要自己调用ProceedingJoinPoint.proceed()来让原始方法执行,其他通知不需要考虑目标方法执行
@Around环绕通知方法的返回值,必须指定为object,来接收原始方法的返回值。
抽取切入点表达式
使用@Pointcut注解抽取切入点表达式
xxxxxxxxxxpackage org.example.learnsys.aop;
import lombok.extern.slf4j.Slf4j;import org.aspectj.lang.ProceedingJoinPoint;import org.aspectj.lang.annotation.Around;import org.aspectj.lang.annotation.Aspect;import org.aspectj.lang.annotation.Before;import org.aspectj.lang.annotation.Pointcut;import org.springframework.stereotype.Component;
// 添加注解public class timeAspect { ("execution(* org.example.learnsys.controller.*.*(..))") public void pointCut() {} // 针对某些特定的业务方法进行测试(如controller),使用 @Around注解设定需要测试的业务 ("pointCut()") public Object timeAspect(ProceedingJoinPoint pjp) throws Throwable { // 获取方法开始时的时间 long startTime = System.currentTimeMillis(); // 运行原始方法 Object result = pjp.proceed(); // 方法运行结束,获取时间,计算耗时 long endTime = System.currentTimeMillis(); log.info(pjp.getSignature()+"process time: {} ms", endTime - startTime); return result; } ("pointCut()") public void before() { log.info("before"); }}
通知顺序
当有多个切面的切入点都匹配到了目标方法,目标方法运行时,多个通知方法都会被执行。
那么,那个通知先执行,哪个通知后执行?
不同切面类中,默认按照切面类的类名字母排序:
目标方法前的通知方法:字母排名靠前的先执行
目标方法后的通知方法:字母排名靠前的后执行
手动控制通知执行顺序方法:
用@Order(数字)加在切面类上来控制顺序
目标方法前的通知方法:数字小的先执行
目标方法后的通知方法:数字小的后执行
切入点表达式
切入点表达式:描述切入点方法的一种表达式
作用:主要用来决定项目中的哪些方法需要加入通知
常见形式:
execution(...)∶根据方法的签名来匹配
@annotation(....):根据注解匹配
execution
execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为:
execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws异常?)
其中带?的表示可以省略的部分
访问修饰符:可省略(比如: public、protected)
包名.类名:可省略(一般不会省略)
throws异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
切入点通配符
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分

..:多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数

注意:根据业务需要,可以使用且(&&)、或(||)、非(!)来组合比较复杂的切入点表达式
建议
所有业务方法名在命名时尽量规范,方便切入点表达式快速匹配。如:查询类方法都是find开头,更新类方法都是update开头。
描述切入点方法通常基于接口描述,而不是直接描述实现类,增强拓展性。
在满足业务需要的前提下,尽量缩小切入点的匹配范围。如:包名匹配尽量不使用...,使用*匹配单个包。
annotation
@annotation切入点表达式,用于匹配标识有特定注解的方法。
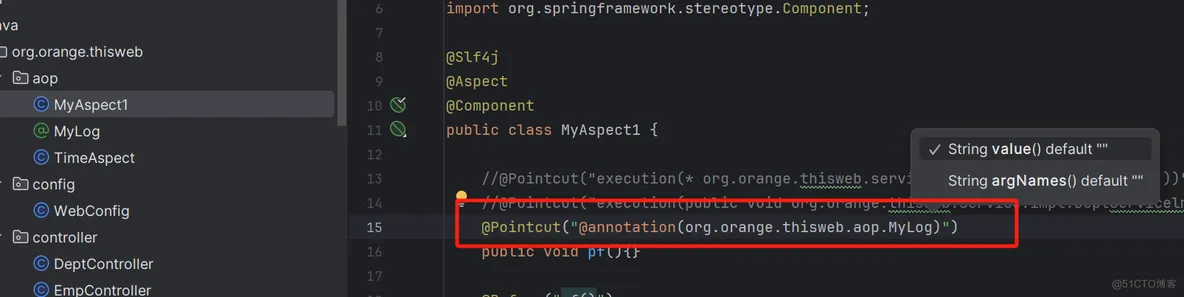
连接点
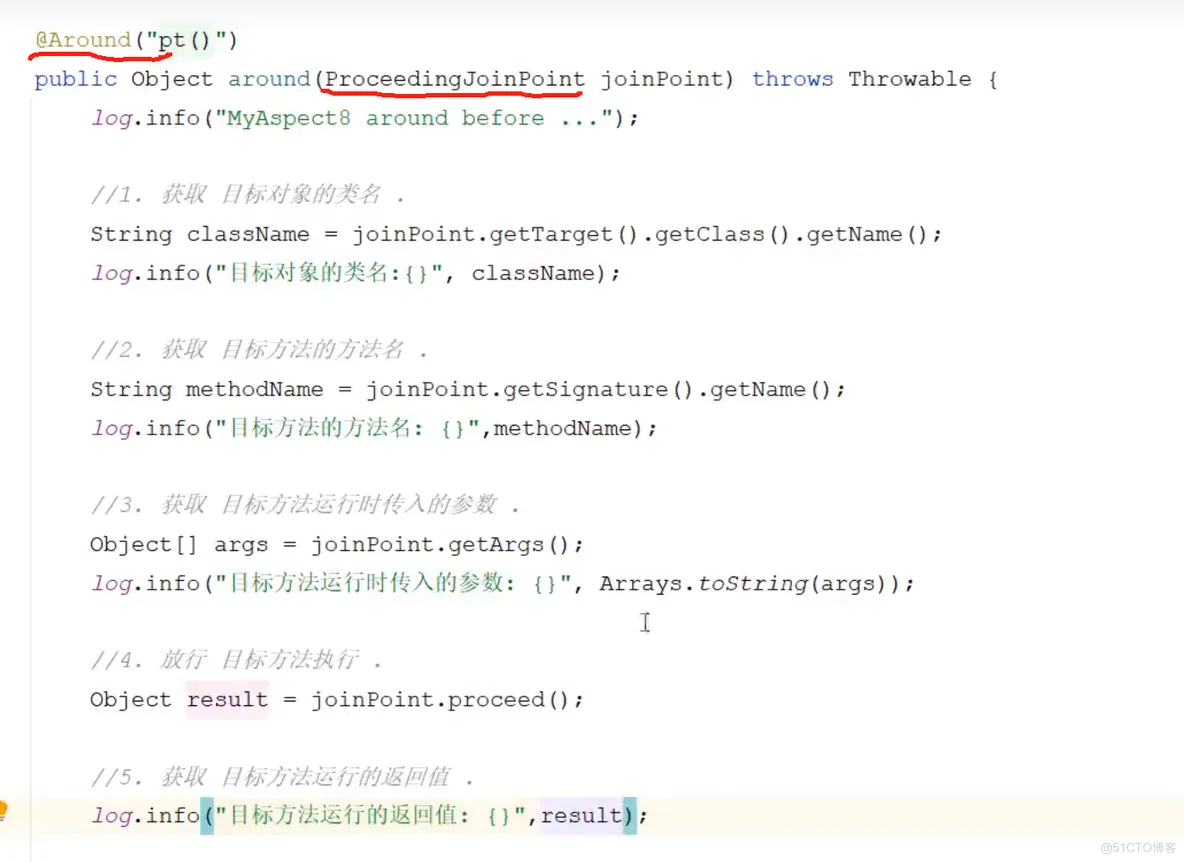
在Spring中用JoinPoint抽象了连接点,用它可以获得方法执行时的相关信息,如目标类名、方法名、方法参数等。
对于@Around通知,获取连接点信息只能使用 ProceedingJoinPoint
对于其他四种通知,获取连接点信息只能使用JoinPoint,它是 ProceedingJoinPoint 的父类型
案例:记录操作日志
将案例中增、删、改相关接口的操作日志记录到数据库表中
需要对所有业务类中的增、删、改方法添加统一功能,使用AOP技术最为方便 @Around环绕通知
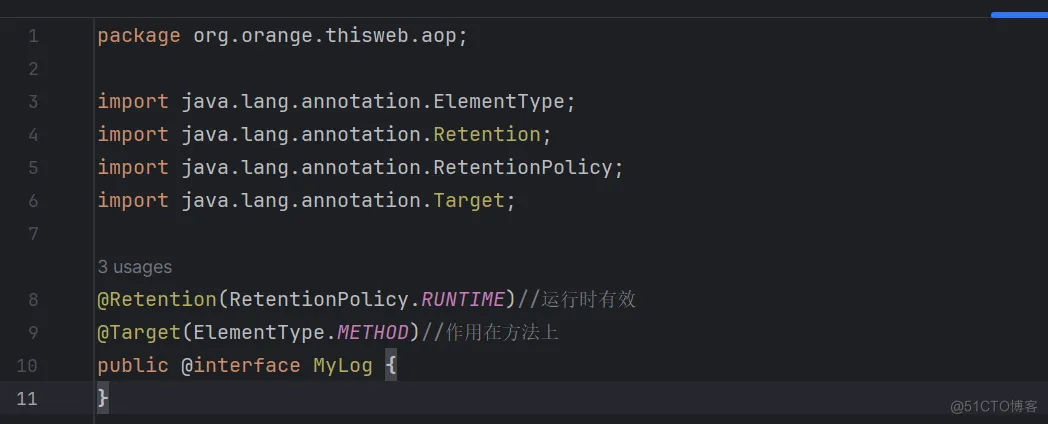
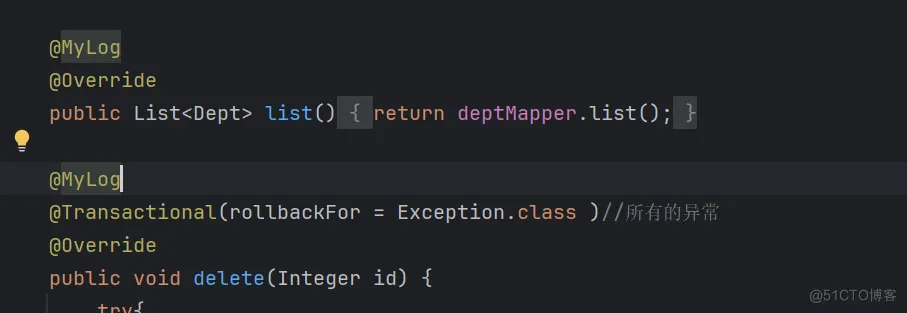
由于增、删、改方法名没有规律,可以自定义 @Log注解完成目标方法匹配
实现方法
准备: 在案例工程中引I入AOP的起步依赖 导入资料中准备好的数据库表结构,并引入对应的实体类
编码: 自定义注解@Log 定义切面类,完成记录操作日志的逻辑
原理篇
配置优先级
在Spring中支持三种配置文件的格式
application.properties
xxxxxxxxxxserver.port=8081application.yml
xxxxxxxxxxserver:port:8082application.yaml
xxxxxxxxxxserver:port:8083
三种配置文件的优先级是:
xxxxxxxxxxapplication.properties > application.yml > application.yaml
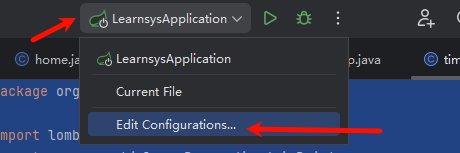
SpringBoot除了支持配置文件属性配置外,还支持Java系统属性和命令行参数的方式进行属性配置
Java系统属性
xxxxxxxxxx-Dserver.port=9000命令行参数
xxxxxxxxxx--server.port=10010
全部配置优先级排序
命令行参数;
ava:comp/env的JNDI属性(当前J2EE应用的环境);
JAVA系统的环境属性;
操作系统的环境变量;
JAR包外部的application-xxx.properties或application-xxx.yml配置文件;
JAR包内部的application-xxx.properties或application-xxx.yml配置文件;
JAR包外部的application.properties或application.yml配置文件;
JAR包内部的application.properties或application.yml配置文件;
@Configuration注解类上的@PropertySource指定的配置文件;
通过SpringApplication.setDefaultProperties 指定的默认属性;
Bean管理
手动获取Bean对象
默认情况下,Spring项目启动时,会把bean都创建好放在lOc容器中,如果想要主动获取这些bean,可以通过如下方式:
根据name获取bean:
xxxxxxxxxxObject getBean(String name)根据类型获取bean:
xxxxxxxxxx<T> T getBean(Class<T> requiredType)根据name获取bean(带类型转换):
xxxxxxxxxx<T> T getBean(String name,Class<T> requiredType)
xxxxxxxxxxprivate ApplicationContext applicationContext;public void testGetBean() {DeptController deptController = (DeptController) applicationContext.getBean("deptController");}在默认状态下,bean是单例模式
bean作用域 Spring支持五种作用域,后三种在web环境才生效:
作用域 说明 singleton 容器内同名称的bean只有一个实例(单例)(默认) prototype 每次使用该bean时会创建新的实例(非单例) request 每个请求范围内会创建新的实例(web环境中,了解) session 每个会话范围内会创建新的实例(web环境中,了解) application 每个应用范围内会创建新的实例(web环境中,了解) 使用
@Scope设置bean作用域xxxxxxxxxx@Scope("prototype")第三方bean 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Component及衍生注解声明bean的,就需要用到
@Bean注解。 若要管理的第三方bean对象,建议对这些bean进行集中分类配置,可以通过@Configuration注解声明一个配置类。使用方法: 在配置类中加入以下方法
xxxxxxxxxx//将方法返回值交给Ioc容器管理,成为Ioc容器的bean对象public SAXReader saxReader(){return new SAXReader();}注意:
通过@Bean注解的name或value属性可以声明bean的名称,如果不指定,默认bean的名称就是方法名。
如果第三方bean需要依赖其它bean对象,直接在bean定义方法中设置形参即可,容器会根据类型自动装配。
springboot原理
对于spring Framework框架来说,它的繁琐是体现在依赖和配置这个方面上,而springboot的出现
优化了这两个点,那是因为springboot底层提供了非常重要的功能,一个是起步依赖,一个是自动配
置,起步依赖大大的简化pom文件当中依赖的配置,就可以解决spring框架中依赖繁琐的问题,而通过
自动配置的功能就可以大大的简化框架在使用时bean的声明以及bean的配置,我们只需要引入程序开发
时所需要的起步依赖,那么所有项目在开发时常见时的配置就都有了,我们之间使用就可以了。
起步依赖
当我们使用spring框架进行web程序开发时,我们就需要引入web程序开发所需要的一些依赖,比如
spring web mvc依赖,这是spring框架进行web程序开发所需要的依赖,还有servlet、jason处理的工具
包jackson、aop相关联的依赖等等,而且引入的这些依赖版本还得匹配,否则就可能出现版本冲突的问题
当我们使用springboot开发时就不需要这么麻烦了,我们只需要引入一个依赖就可以了,web开的的起步依赖
这个依赖集成了所有web开发的常见依赖,只要引入这一个依赖,其他的依赖都会通过maven的依赖传递进来
依赖传递指的就是如果a依赖了b,b依赖了c,c依赖的d,那么引入a以后b、c、d这些依赖都会被引入
所以起步依赖的原理的就是maven的依赖传递
自动配置
SpringBoot的自动配置就是当spring容器启动后,一些配置类、bean对象就自动存入到了IOC容器中,不需要我们手动去声明,从而简化了开发,省去了繁琐的配置操作。
自动配置原理
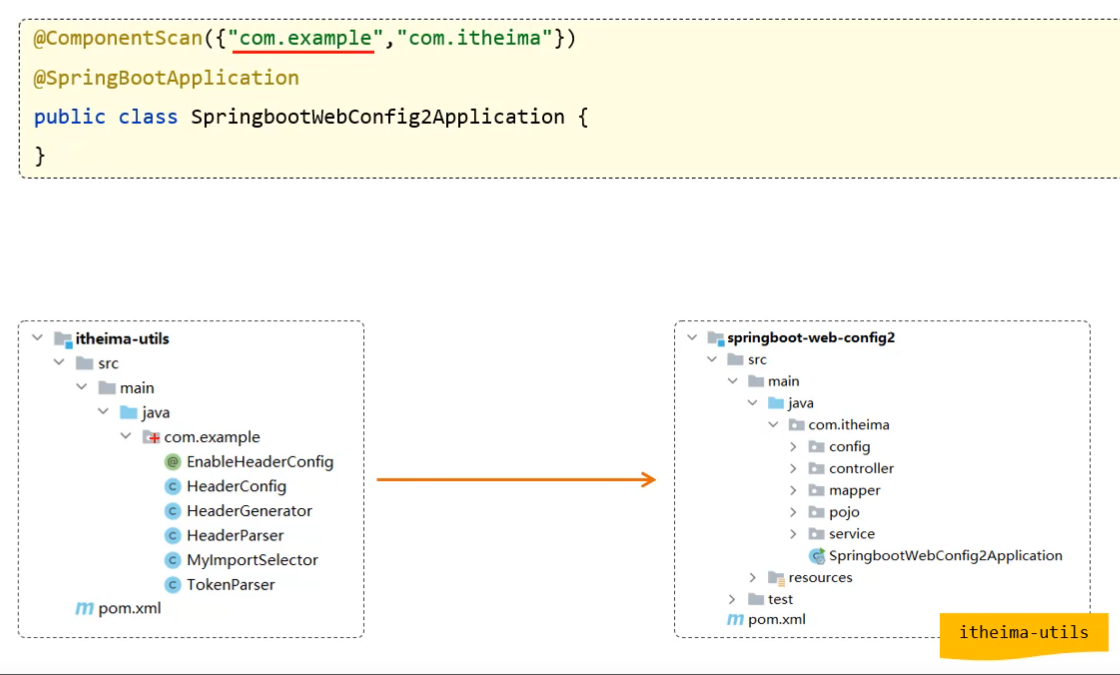
SpringBoot只能扫描所在包及其子包,扫描不到其他包。
使用@ComponentScan组件扫描,指定需要扫描的包
使用
@Import导入。使用@Import导入的类会被Spring加载到IOC容器中,导入形式主要包括以下几种。导入普通类
导入配置类
导入ImportSelector接口实现的类
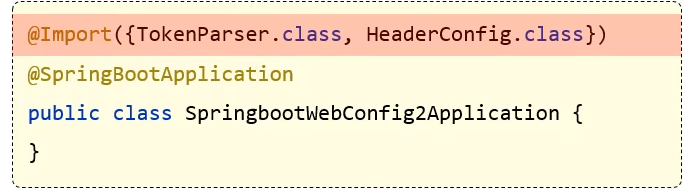
@EnableXxxx注解,封装@Import注解 但是在实际开发中,如果我们用上面的方式是不是还得清楚的知道我们到底要导入这个第三方依赖中哪些配置类和哪些bean对象,这还是有点繁琐了,我们反过来想,我们要导入哪些配置类和bean对象谁最清楚?是不是第三方依赖最清楚,所以让第三方依赖自己指定导入哪些配置类和bean对象
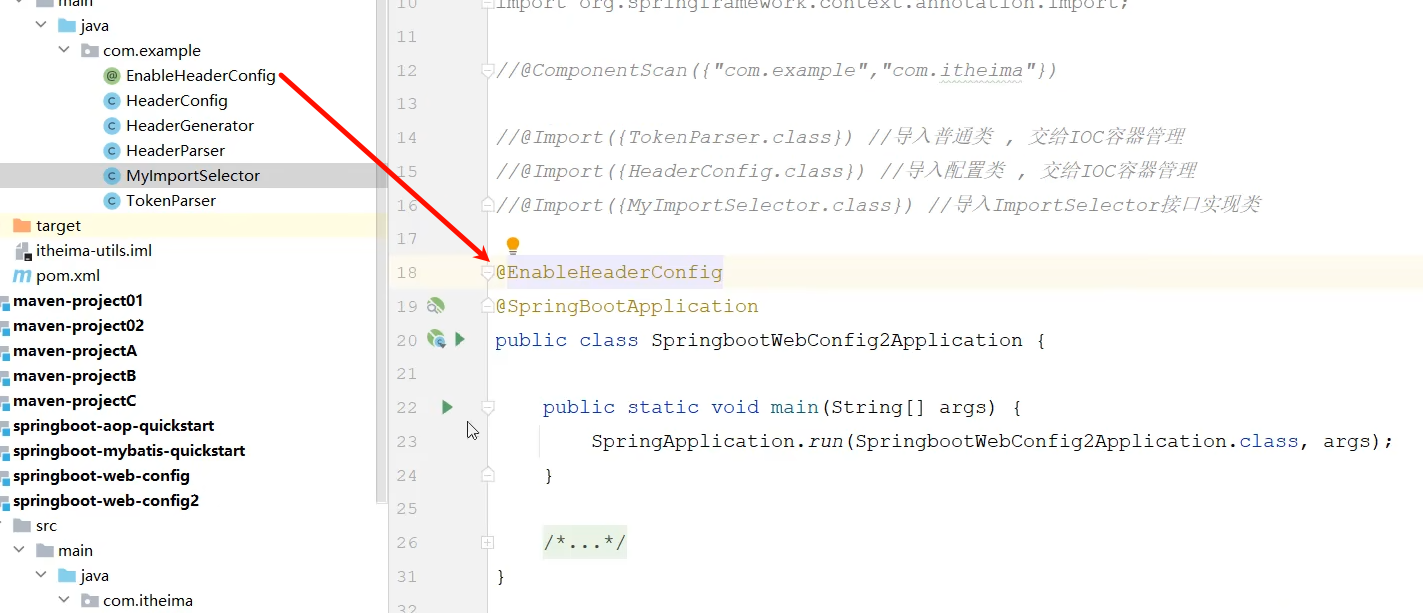
@Conditional 作用:按照一定的条件进行判断,在满足给定条件后才会注册对应的bean对象到SpringIOc容器中。 位置:方法、类
@Conditional本身是一个父注解,派生出大量的子注解:
@ConditionalOnClass:判断环境中是否有对应字节码文件,才注册bean到Ioc容器。
@ConditionalOnMissingBean:判断环境中没有对应的bean(类型或名称),才注册bean到iOc容器。
@ConditionalOnProperty:判断配置文件中有对应属性和值,才注册bean到ioc容器。
总结
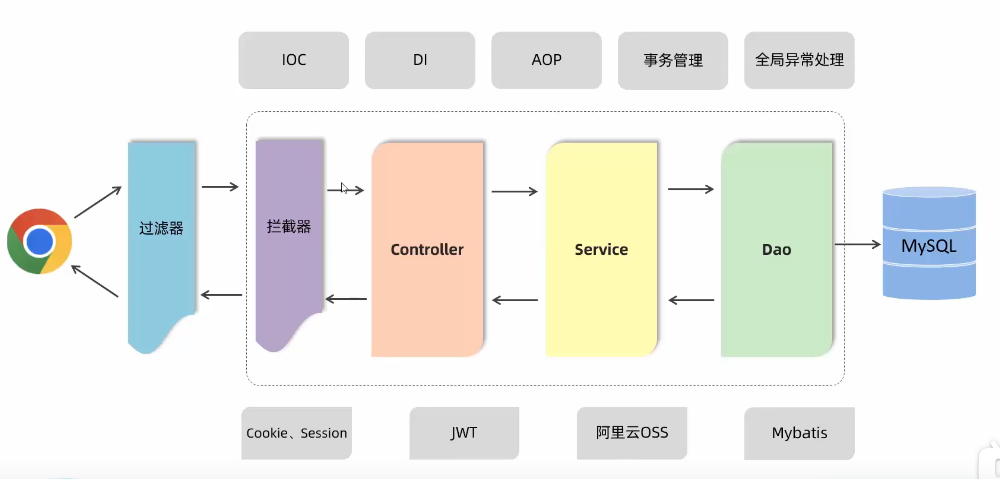
在WEB后端开发中,一般都是基于标准三层架构进行开发。
Controller负责接收响应请求
server层负责业务逻辑操作
dao处理访问操作
模块功能来源
Maven高级
分模块设计与开发
为什么要使用分模块设计与开发?
如果不进行分模块开发时,所有的业务代码都在一个模块中,随着业务越来越强大,这个项目中的业务代码会越来越多。会导致项目难以维护,代码难以复用。
在项目设计是,可以将项目进行分模块设计。
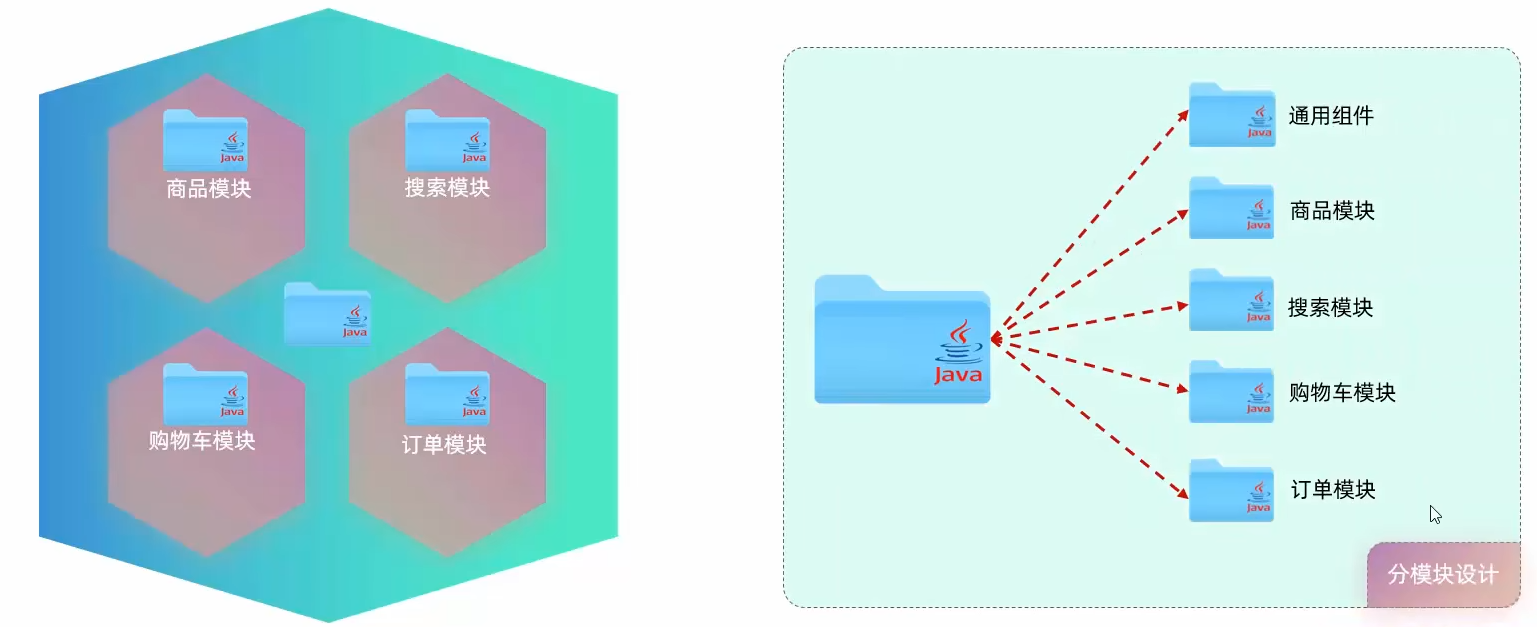
分模块开发
需求:将项目中的pojo实体类和utils工具类抽取到响应的模块中

注意!分模块开发需要先针对模块功能进行设计,再进行编码。不会先将工程开发完毕,然后进行拆分。
完成拆分后,在项目需要用到该模块时,只需要在pom文件中引入即可


继承与聚合
继承
在maven中,工程也可以实现继承关系
在项目中,每个模块可能都会使用到一个相同的依赖,如果每个模块导入一次,操作非常繁琐,也不便于管理

继承
介绍:继承描述的是两个工程间的关系,与java中的继承相似,子工程可以继承父工程中的配置信息,常见于依赖关系的继承。
作用:简化依赖配置、统一管理依赖
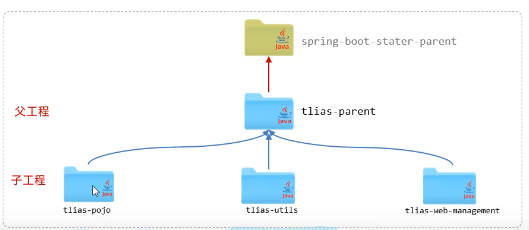
实现:使用<parent>...</parent>标签
由于依赖只能单继承,需要让父工程继承SpringBoot依赖,再让子工程继承父工程,通过依赖传递将这个依赖传递到子工程
xxxxxxxxxx<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.3.2</version> <relativePath/> <!-- lookup parent from repository --></parent>
步骤
创建maven模块tlias-parent,该工程为父工程,设置打包方式pom(默认jar)。 打包方式:
jar:普通模块打包,springboot项目基本都是jar包(内嵌tomcat运行)
war:普通web程序打包,需要部署在外部的tomcat服务器中运行
pom:父工程或聚合工程,该模块不写代码,仅进行依赖管理
在pom文件中使用标签
<packaging>设置打包方式xxxxxxxxxx<packaging>pom</packaging>在子工程的pom.xml文件中,配置继承关系。
xxxxxxxxxx<parent><groupId>com.itheima</groupId><artifactId>tlias-parent</artifactId><version>1.0-SNAPSHOT</version><relativePath>../ tlias-parent/pom.xml</relativePath><!-- 指定父工程的POM文件 --></parent>在父工程中配置各个工程共有的依赖(子工程会自动继承父工程的依赖)。
版本锁定
什么是版本锁定?
在真实项目开发中,由于业务非常复杂,一个项目通常都是分模块、多人协作开发的,不可能一个人大包大揽,从头写到尾。必然会出现这样一种场景:crm-dao子模块是由程序员A开发的,crm-service子模块是由程序员B开发的,crm-web子模块是由程序员C开发的,当程序员A开发完crm-dao子模块后,他必然就要编写[JUnit单元测试用例了,这时,他就要在其pom.xml文件中添加JUnit的依赖了,假设添加的依赖如下:
xxxxxxxxxx<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.2</version> <scope>test</scope> </dependency></dependencies>12345678同理,当程序员B开发完crm-service子模块后,他必然也要编写JUnit单元测试用例,这时,他也要在其pom.xml文件中添加JUnit的依赖了,假设添加的依赖如下:
xxxxxxxxxx<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.0</version> <scope>test</scope> </dependency></dependencies>12345678可以发现程序员A与程序员B他俩所使用的junit的版本不一致,这样不是太好。合适的方法是一开始就由技术经理在父工程中统一好所使用的junit的版本。这样,每个程序员开发完自己对应的子模块之后,在编写JUnit单元测试用例时,都将使用统一版本的junit。
所以可以通过版本锁定来统一管理JAR包的版本
面对众多的依赖,有一种方法不用考虑依赖路径、声明顺序等因素而可以采用直接锁定版本的方法确定依赖构件的版本,版本锁定后则不用考虑依赖的声明顺序或依赖的路径,以锁定的版本为准添加到工程中,此方法在企业开发中很常用。
在maven中,可以在父工程的pom文件中通过<dependencyManagement>标签来统一管理依赖版本。
配置示例:
xxxxxxxxxx<dependencyManagement> <dependencies> <!--JWT令牌--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.9</version> <scope>test</scope> </dependency> </dependencies></dependencyManagement>注意:
通过
<dependencyManagement>配置,仅仅代表统一管理该依赖版本,而并不会将该依赖加入进来。如果在子工程中需要使用到这个依赖,我们需要手动进行引入。
子工程引l入依赖时,无需指定
<version>版本号,父工程统一管理。变更依赖版本,只需在父工程中统一变更。
自定义属性/引用属性
在大型的项目中,可能需要非常非常多的依赖,这些依赖的版本号分散在POM文件中,不便于查找和管理,可以使用自定义属性/引用属性解决
自定义属性
xxxxxxxxxx<properties><lombok.version>1.18.24</1ombok.version><jjwt.version>0.9.0</jjwt.version></properties>引用属性
xxxxxxxxxx<dependencyManagement><dependencies><!-- JWT令牌 --><dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>${jjwt.version}</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version></dependency></dependencies></dependencyManagement>
思考(⭐)
<dependencyManagement>与<dependencies>的区别是什么?
<dependencies>是直接依赖,在父工程配置了依赖,子工程会直接继承下来。<dependencyManagement>是统一管理依赖版本,不会直接依赖,还需要在子工程中引入所需依赖(无需指定版本)
聚合
什么是聚合?
在一个大型项目中,依赖配置可能非常复杂,如果需要对一个模块进行打包发布,需要先打包其父工程和其他依赖模块为jar安装到本地操作,才能完成打包。这样非常麻烦。
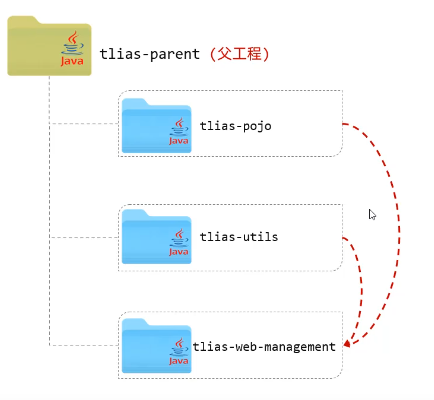
可以使用maven聚合来解决以上问题。
聚合:将多个模块组织成一个整体,同时进行项目的构建。
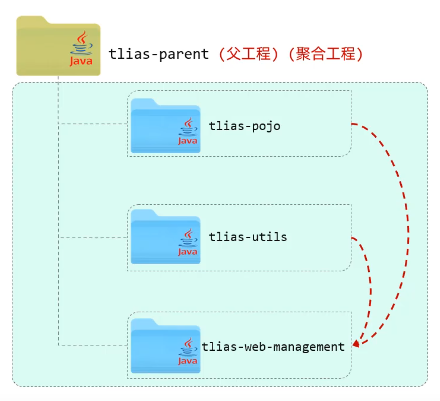
通过聚合工程实现
介绍:一个不具有业务功能的“空”工程(有且仅有一个pom文件)
作用:快速构建项目(无需根据依赖关系手动构建,直接在聚合工程上构建即可)
父工程也可以作为聚合工程。
在maven中可以通过<modules>设置当前聚合工程所包含的子模块名称
xxxxxxxxxx<!--聚合--><modules> <module>../tlias-pojo</module> <module>../tlias-utils</module> <module>../tlias-web-management</module></modules>注意:聚合工程中所包含的模块,在构建时,会自动根据模块间的依赖关系设置构建顺序,与聚合工程中模块的配置书写位置无关。
总结
作用
聚合用于快速构建项目
继承用于简化依赖配置、统一管理依赖
相同点:
聚合与继承的pom.xml文件打包方式均为pom,可以将两种关系制作到同一个pom文件中
聚合与继承均属于设计型模块,并无实际的模块内容
不同点:
聚合是在聚合工程中配置关系,聚合可以感知到参与聚合的模块有哪些
继承是在子模块中配置关系,父模块无法感知哪些子模块继承了自己
私服
如果在公司中多个项目模块中的的公共类用的都是一样的,那么不可能将这些一样的代码写两遍。所以将其中一个项目中的代码打包成私服,然后在另外一个模块中去进行引用。
除此之外,如果大公司中开发人员较多,大家同时去远程仓库将依赖下载到本地,那么对公司的带宽会造成很大的压力。很有可能会造成其他的问题。所以可以在公司的局域网内部去搭建一台服务器,开发人员所有的依赖去这台服务器中去访问,如果该台服务器中也没有该依赖,那么该服务器就去远程仓库查找,然后下载到该服务器,最后在返给开发者。
私服是一种特殊的远程仓库,它是架设在局域网内的仓库服务,用来代理位于外部的中央仓库,用于解决团队内部的资源共享与资源同步问题。
xxxxxxxxxx优点:1、加速下载速度2、加速带宽,加速项目构建速度3、方便公共使用4、提高maven稳定性,中央仓库需要连外网才能访问,私服只需要连内网就可以访问。
xxxxxxxxxx依赖查找顺序:- 本地仓库- 私服- 中央仓库
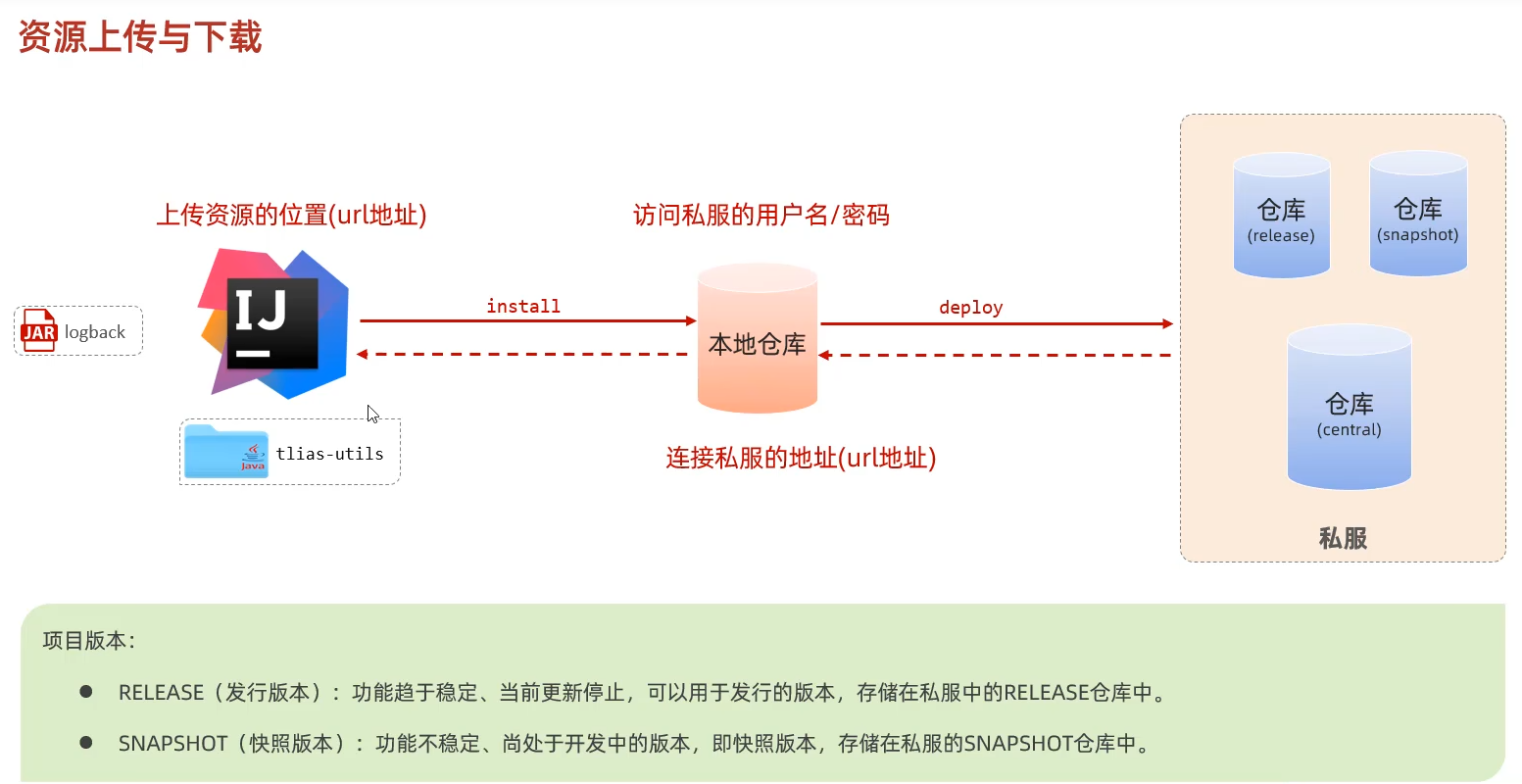
私服配置说明
访问私服:http://192.168.150.101:8081
访问密码:admin/admin
使用私服,需要在maven的settings.xml配置文件中,做如下配置:
需要在 servers 标签中,配置访问私服的个人凭证(访问的用户名和密码)
xxxxxxxxxx<server><id>maven-releases</id><username>admin</username><password>admin</password></server><server><id>maven-snapshots</id><username>admin</username><password>admin</password></server>在 mirrors 中只配置我们自己私服的连接地址(如果之前配置过阿里云,需要直接替换掉)
xxxxxxxxxx<mirror><id>maven-public</id><mirrorOf>*</mirrorOf><url>http://192.168.150.101:8081/repository/maven-public/</url></mirror>需要在 profiles 中,增加如下配置,来指定snapshot快照版本的依赖,依然允许使用
xxxxxxxxxx<profile><id>allow-snapshots</id><activation><activeByDefault>true</activeByDefault></activation><repositories><repository><id>maven-public</id><url>http://192.168.150.101:8081/repository/maven-public/</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories></profile>如果需要上传自己的项目到私服上,需要在项目的pom.xml文件中,增加如下配置,来配置项目发布的地址(也就是私服的地址)
xxxxxxxxxx<distributionManagement><!-- release版本的发布地址 --><repository><id>maven-releases</id><url>http://192.168.150.101:8081/repository/maven-releases/</url></repository><!-- snapshot版本的发布地址 --><snapshotRepository><id>maven-snapshots</id><url>http://192.168.150.101:8081/repository/maven-snapshots/</url></snapshotRepository></distributionManagement>发布项目,直接运行 deploy 生命周期即可 (发布时,建议跳过单元测试)
总结
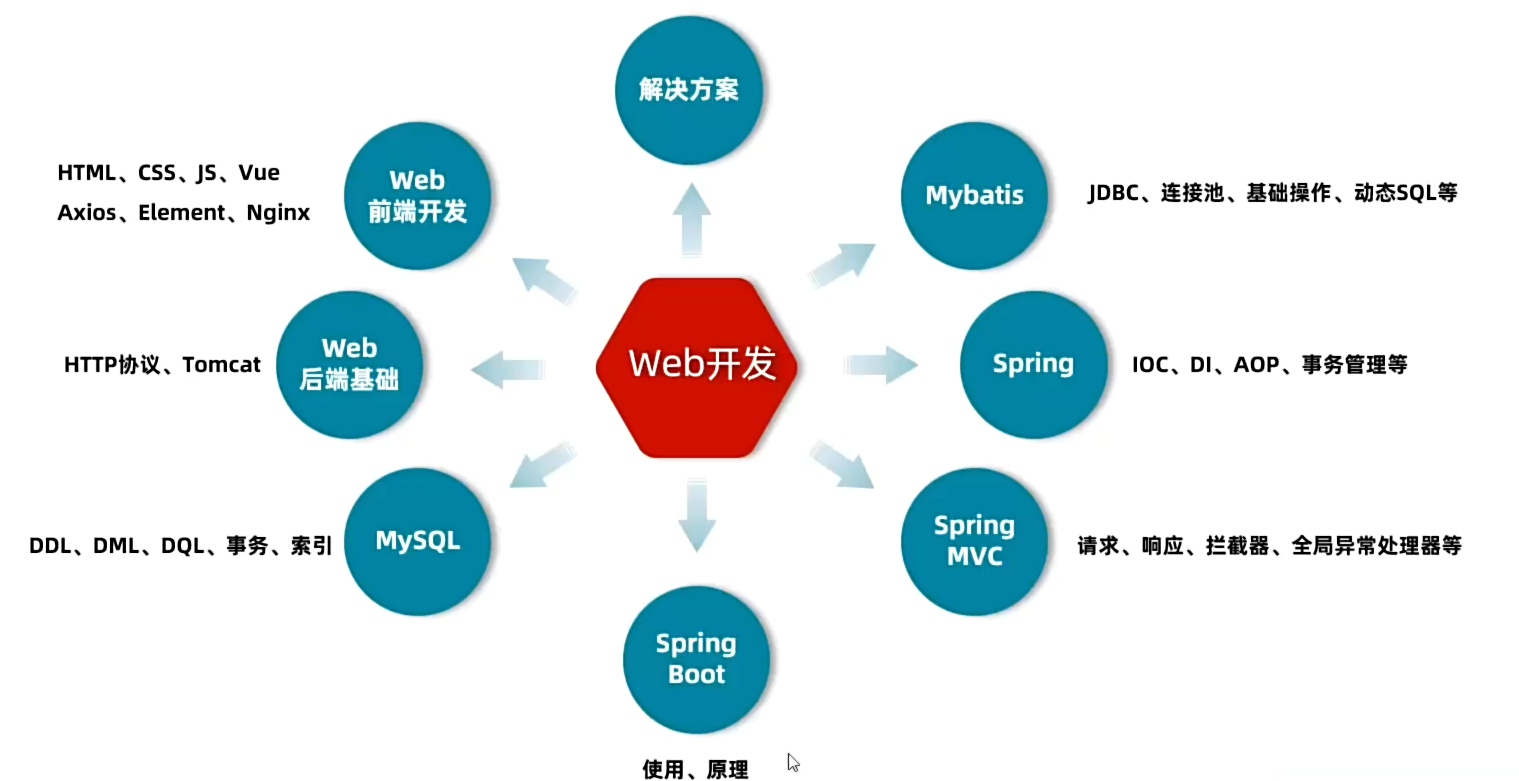
课程框架
笔记到此结束,谢谢!
笔记最后编辑时间:2025.02.19
笔记字数:24100余字
完结撒花❀❀❀❀❀❀